skirts <- read_csv("data/skirts.txt", skip = 4)
skirts_ts <- ts(skirts, start = c(1866))
skirts_df <- data.frame(
time = time(skirts_ts),
skirt = unname(skirts)
)
ggplot(skirts_df, aes(time, skirt)) +
geom_line()时间序列算法
Time Series Algorithms
时间序列
时间序列是现实生活中经常会碰到的数据形式。例如北京市连续一年的日平均气温、某股票的股票价格、电商平台上某件商品的日销售件数等等。时间序列分析的目的是挖掘时间序列中隐含的信息与模式,并借此对此序列数据进行评估以及对序列的后续走势进行预测。

白噪声
考虑一个时间序列,其中每一个元素为独立同分布变量,且均值为 0。这种时间序列叫做白噪声。之所以叫这个名字,是因为对这种序列的频域分析表明其中平等的包含了各个频率,和物理中的白光类似。
每个元素服从 \(N\left(0, 1\right)\),均值 \(\mu_t = 0\),方差 \(\sigma_t^2 = 1\)。每个元素独立,对于任何 \(t \neq s\),\(\gamma_{t, s} = 0\),\(\rho_{t, s} = 0\)。
我们一般用 \(e\) 表示白噪声,将白噪声序列写作:
\[ \left\{e_1, e_2, ..., e_t, ...\right\} \]

白噪声
考虑一个时间序列,在 \(t\) 时刻的值是白噪声前 \(t\) 个值之和,设 \(\left\{e_1, e_2, ..., e_t, ...\right\}\) 为标准正态的白噪声,则:
\[ \begin{split} Y_1 &= e_1 \\ Y_2 &= e_1 + e_2 \\ &\vdots \\ Y_t &= e_1 + e_2 + ... + e_t \\ &\vdots \end{split} \]
\(\mu_t = E\left(e_1 + ... + e_t\right) = E\left(e_1\right) + ... + E\left(e_t\right) = 0\)
\(\sigma_t^2 = Var\left(e_1 + ... + e_t\right) = Var\left(e_1\right) + ... + Var\left(e_t\right) = t \sigma^2\)
统计上可以看出随机游走的“趋势性”实际是个假象,因为其均值一直是白噪声的均值,不存在偏离的期望。但方差与时间呈线性增长并且趋向于无穷大,这意味着只要时间够长,随机游走的序列值可以偏离均值任意远,但期望永远在均值处。物理与经济学中很多现象被看做是随机游走,例如分子布朗运动,股票价格走势等。

ARIMA 模型
ARIMA 模型(Autoregressive Integrated Moving Average model),差分整合移动平均自回归模型,又称整合移动平均自回归模型(移动也可称作滑动),是时间序列预测分析方法之一。
\(\text{ARIMA} \left(p, d, q\right)\) 中,\(\text{AR}\) 是自回归,\(p\) 为自回归项数;\(\text{MA}\) 为滑动平均,\(q\) 为滑动平均项数,\(d\) 为使之成为平稳序列所做的差分次数(阶数)。

ARIMA 模型
skirts.txt 数据记录了 1866 年到 1911 年每年女人们裙子的直径:
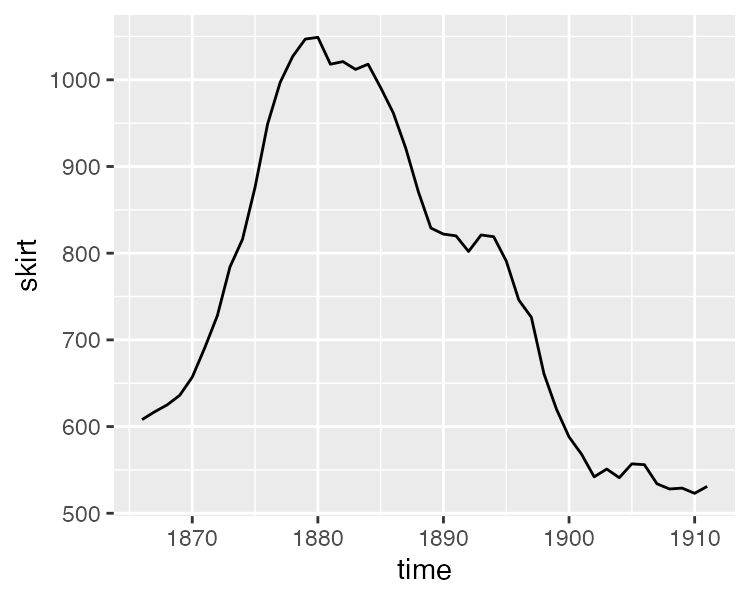
ARIMA 模型
skirts_arima |> forecast(h = 6) |> autoplot(lim.size = 3) +
theme(text = element_text(size = 25)) + theme(title = element_blank())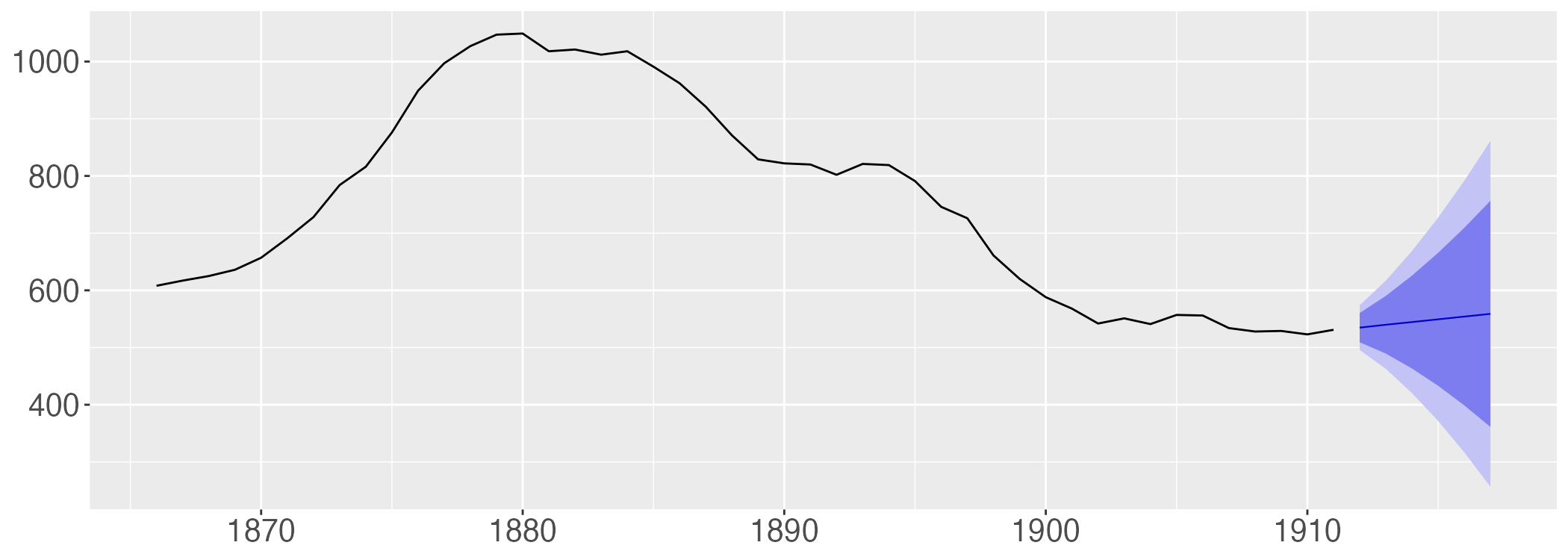
季节性分析
nybirths.txt 数据记录了从 1946 年 1 月到 1959 年 12 月的纽约每月出生人口数量,纽约每月出生人口数量是在夏季有峰值、冬季有低谷的时间序列。
nybirths <- read_csv(
"data/nybirths.txt", col_names = F)
nybirths_ts <- ts(
nybirths, frequency = 12, start = c(1946, 1))
nybirths_df <- data.frame(
time = time(nybirths_ts), nybirths = unname(nybirths))
ggplot(nybirths_df, aes(time, nybirths)) +
geom_line()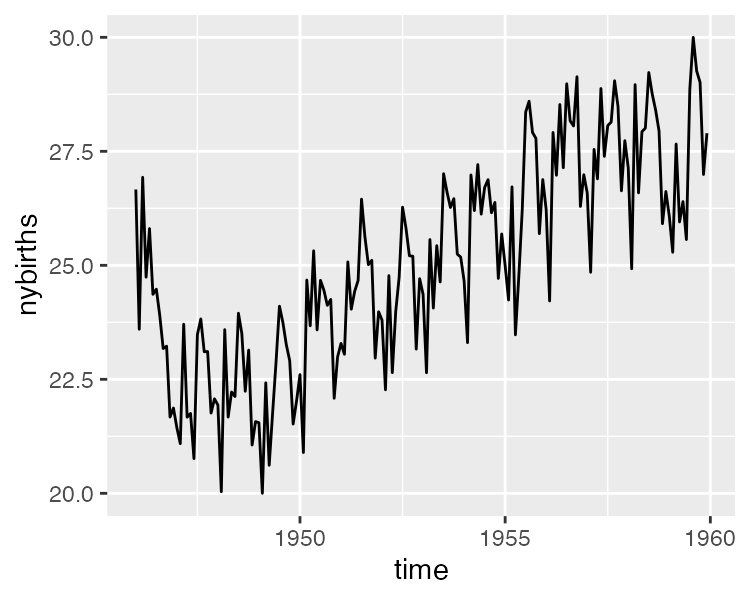
季节性分析
nybirths_components <- decompose(nybirths_ts)
plot(nybirths_components)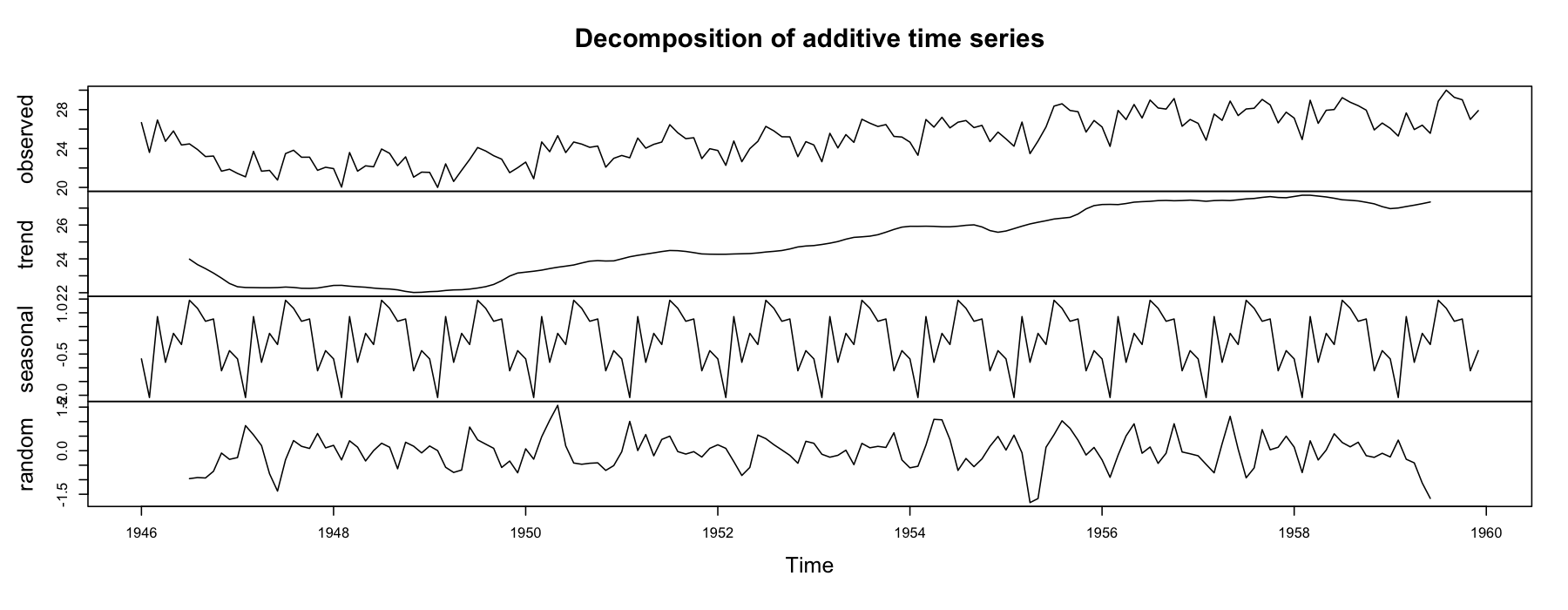
季节性分析
library(ggseas)
ggsdc(nybirths_df, aes(time, nybirths), method = "decompose") + geom_line()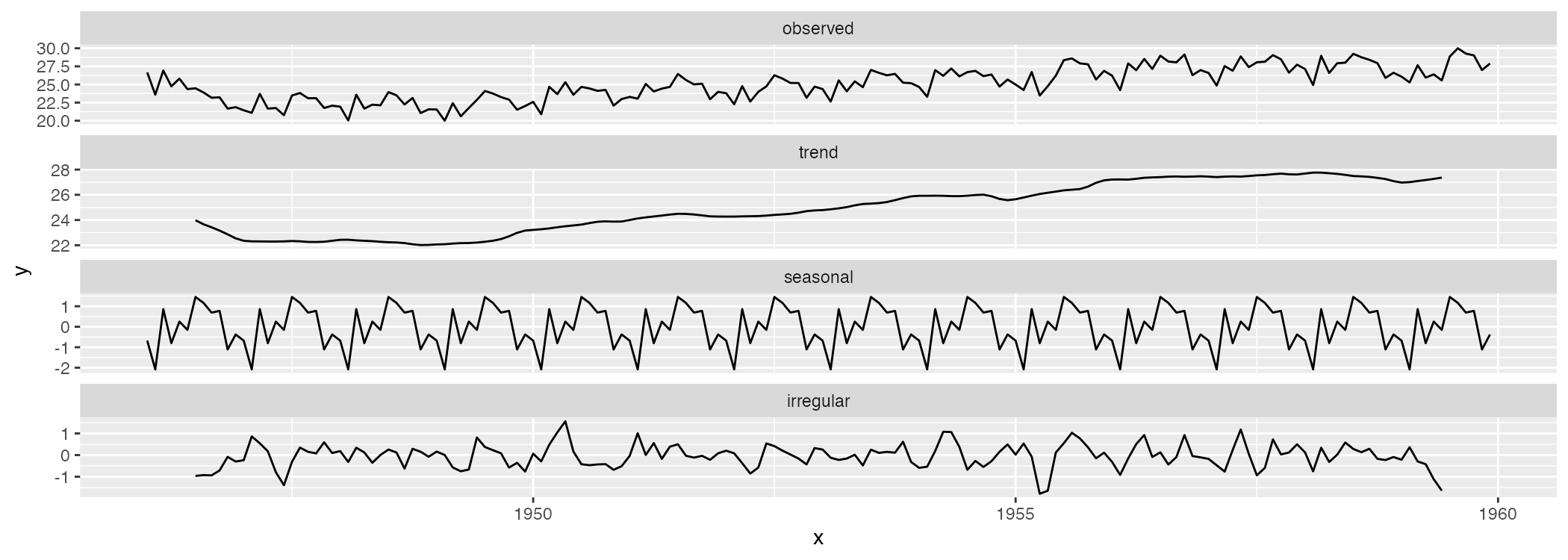
Prophet 入门
利用 predict() 函数可以获取预测值,预测值保存在数据框的 yhat 列内。
forecast <- predict(m, future)
tail(forecast[
c("ds", "yhat", "yhat_lower", "yhat_upper")]) ds yhat yhat_lower yhat_upper
3265 2017-01-14 7.826110 7.115794 8.556095
3266 2017-01-15 8.207902 7.441911 8.920703
3267 2017-01-16 8.532922 7.801880 9.294321
3268 2017-01-17 8.320345 7.590050 9.019720
3269 2017-01-18 8.152951 7.407837 8.917240
3270 2017-01-19 8.164883 7.417012 8.888017利用 plot() 可以对预测结果进行可视化:
plot(m, forecast)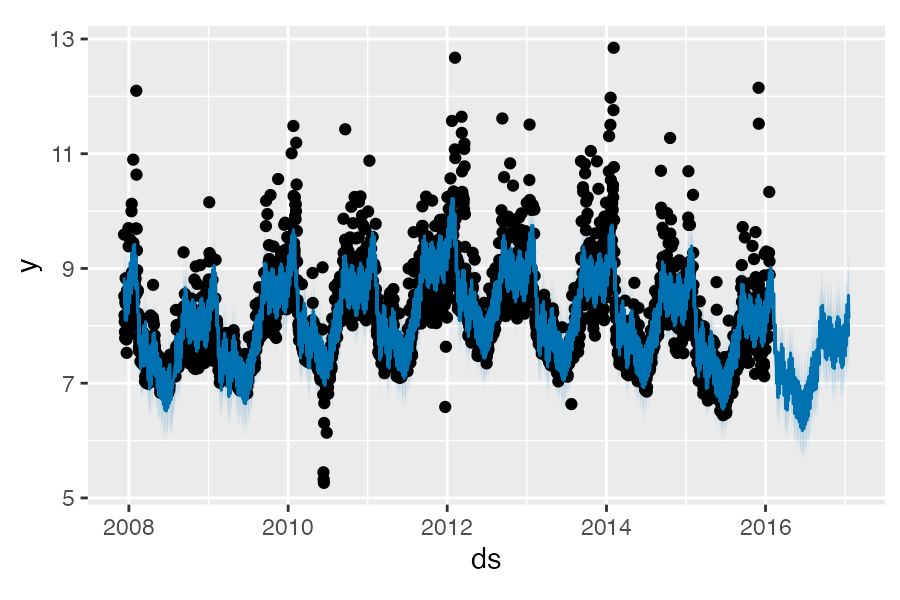
Prophet 入门
利用 prophet_plot_components() 函数可以展示预测值的组成部分。
默认情况下包含趋势,年季节性,周季节性。当模型包含节假日效应时,图中也会展现该部分。
prophet_plot_components(m, forecast)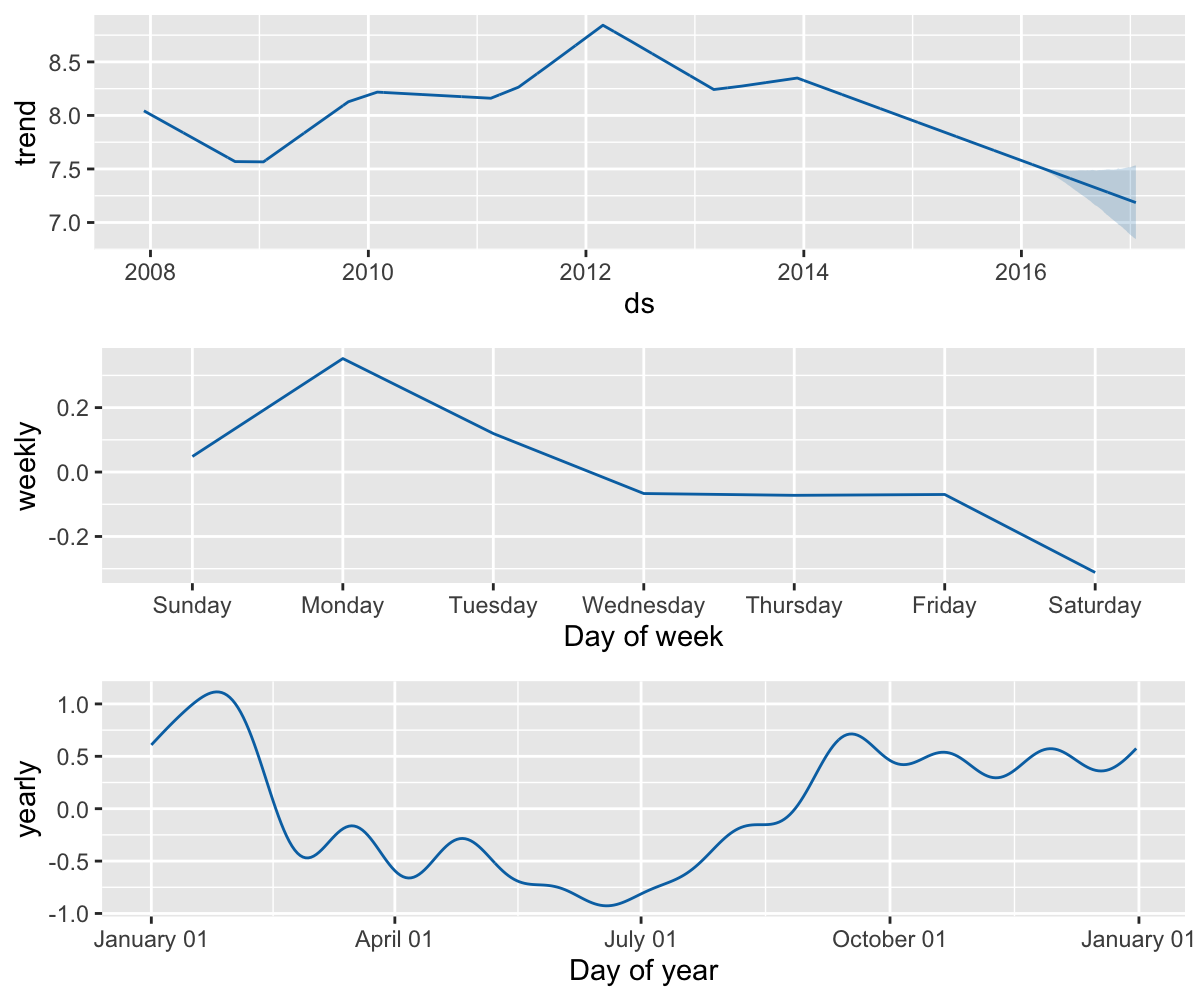
Prophet 预测增长
类似之前,我们需要创建一个用于预测的数据框,除此之外我们还需要指定一个承载能力。
在这里,我们将承载能力设置为同历史值相同,并预测未来 5 年的结果:
future <- make_future_dataframe(m, periods = 1826)
future$cap <- 8.5
fcst <- predict(m, future)
plot(m, fcst)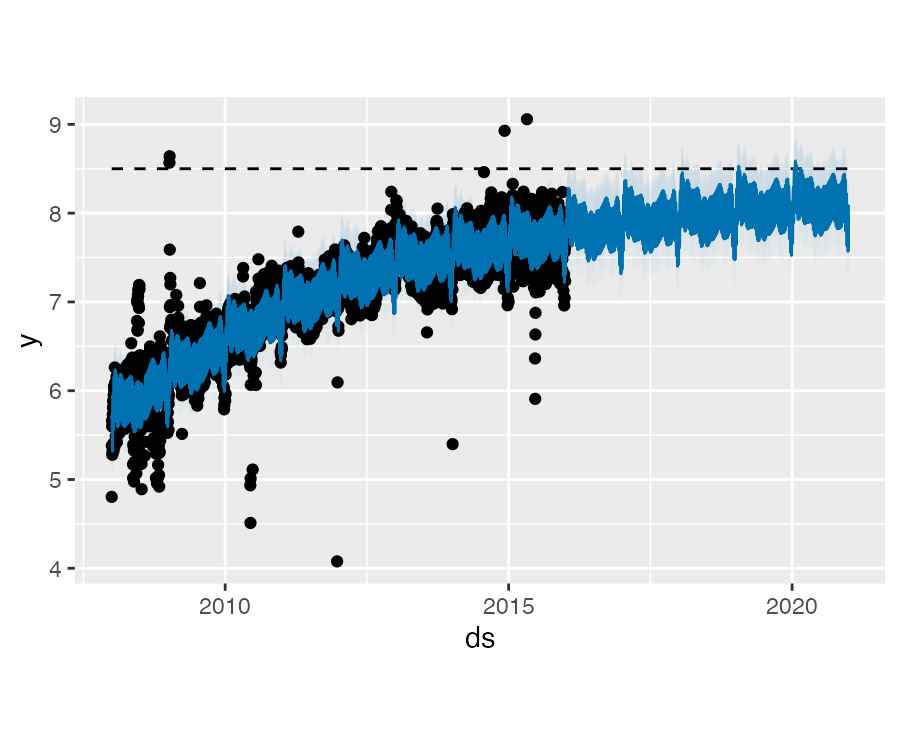
Prophet 预测增长
Logistic Growth 模型同时可以处理预测饱和的最小值,指定最小值的方式同预测增长一样:
df$y <- 10 - df$y
df$cap <- 6
df$floor <- 1.5
future$cap <- 6
future$floor <- 1.5
m <- prophet(df, growth = "logistic")
fcst <- predict(m, future)
plot(m, fcst)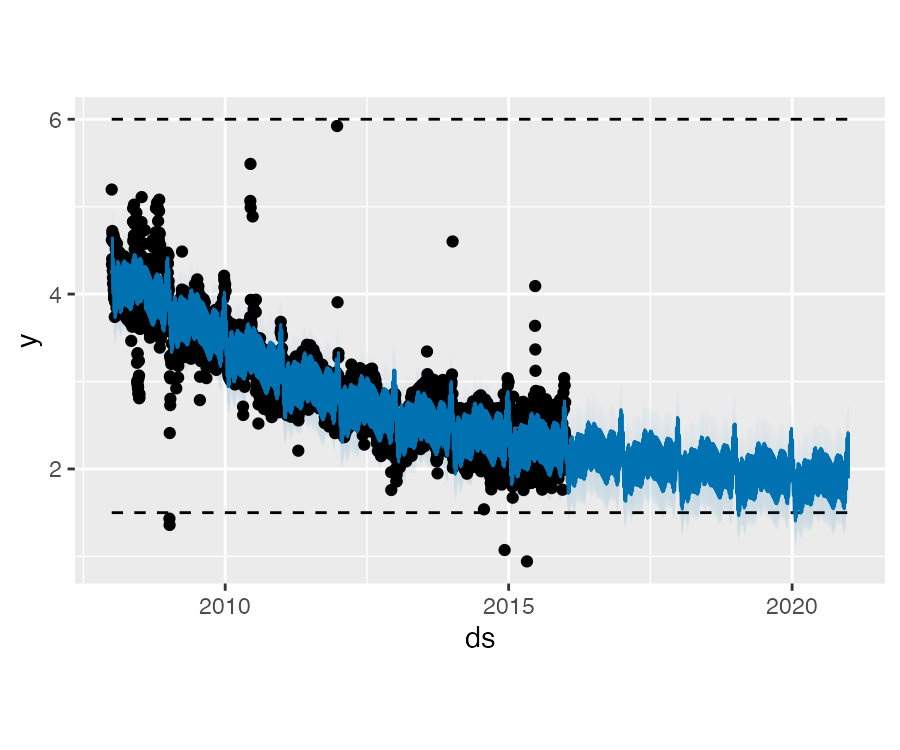
Prophet 趋势突变点
以之前的 Peyton Manning 页面的浏览量数据为例,默认情况下,Prophet 会识别出 25 个潜在的突变点(均匀分布在在前 80% 的时间序列数据中)。下图中的竖线指出这些潜在的突变点所在的位置:
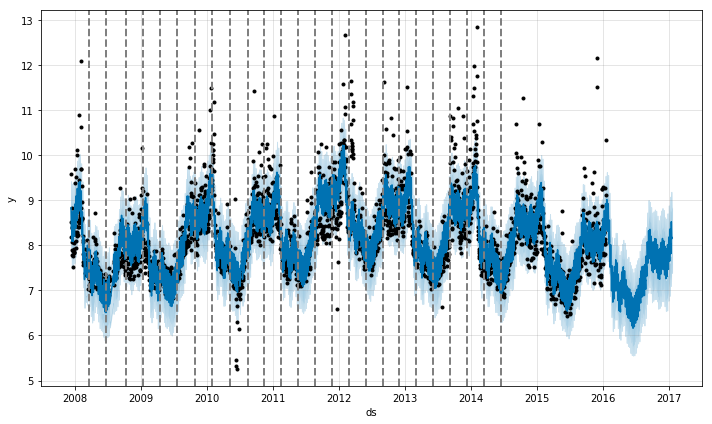
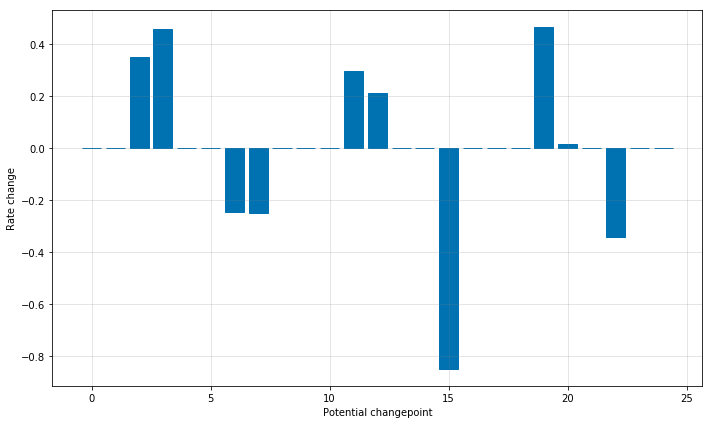
虽然存在很多变化速率可能会突变的点,但由于做了稀疏先验,绝大多数突变点并不会包含在建模过程中。如下图示,通过观察对每个突变点绘制的速率变化值图,可以发现这一点:
Prophet 趋势突变点
潜在突变点的数量可以通过设置 n_changepoints 参数来指定,但最好还是利用调整正则化过程来自动修正。
df = read_csv("data/example_wp_log_peyton_manning.csv")
m <- prophet(df)
future <- make_future_dataframe(m, periods = 365)
forecast <- predict(m, future)
plot(m, forecast) + add_changepoints_to_plot(m)默认情况下,仅在时间序列的前 80% 推断突变点,以便有足够的空间来预测趋势并避免在时间序列末尾过拟合。默认值在大多数情况下是适用的,通过 changepoint_range 可以对其进行设置。
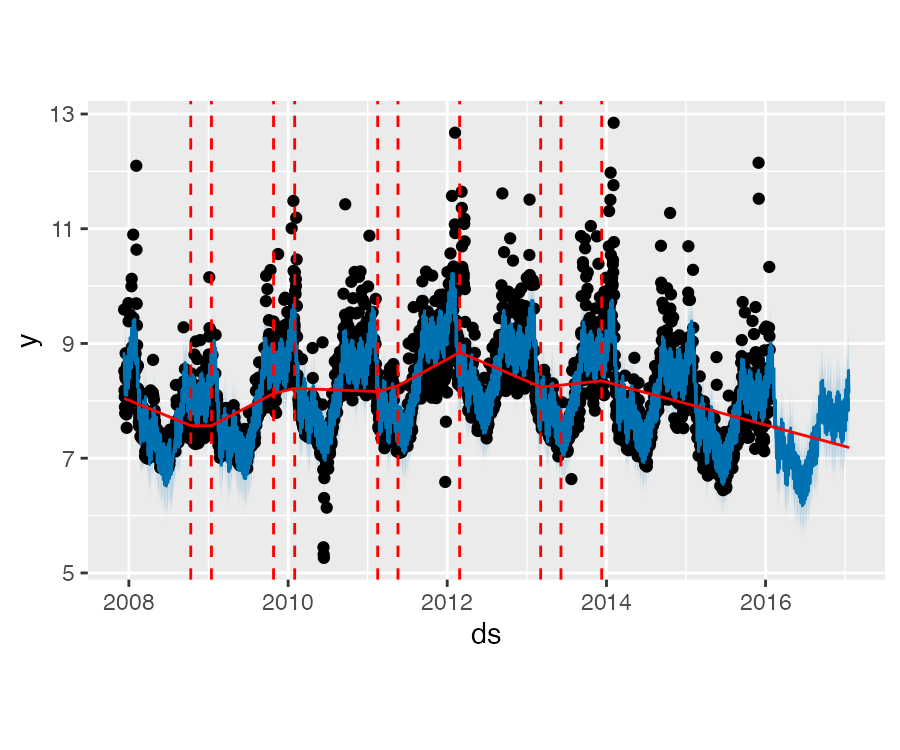
Prophet 趋势突变点
如果趋势变化过拟合(过于灵活)或欠拟合(灵活性不够),可以通过 changepoint.prior.scale 参数调整稀疏先验程度。默认情况下,参数值为 0.05,增加这个值会导致趋势拟合得更加灵活:
m <- prophet(df, changepoint.prior.scale = 0.5)
future <- make_future_dataframe(m, periods = 365)
forecast <- predict(m, future)
plot(m, forecast)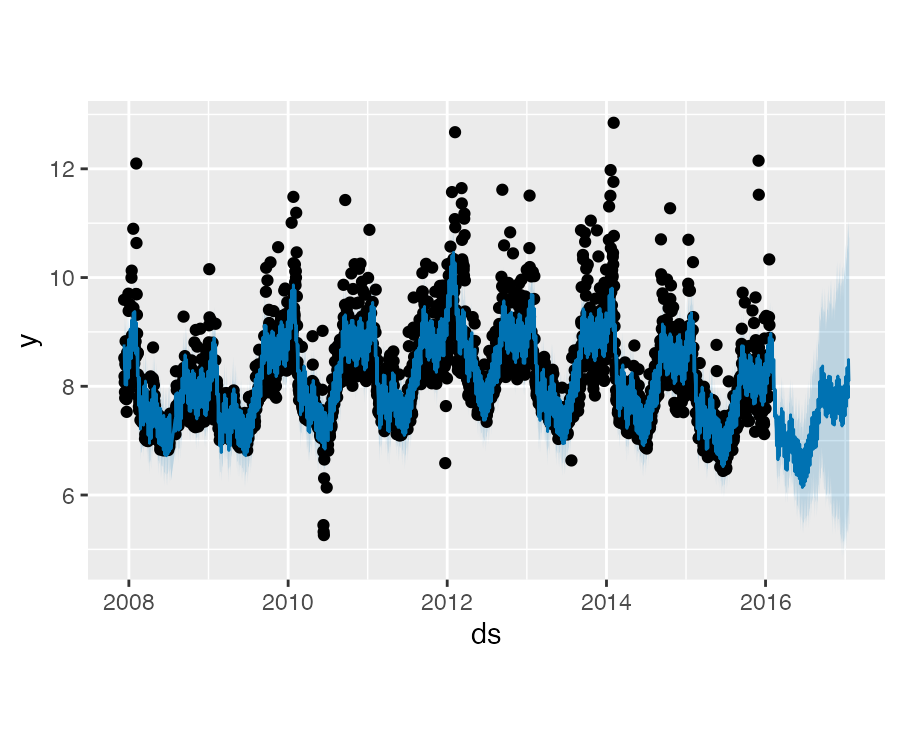
Prophet 趋势突变点
减少这个值,会导致趋势拟合得灵活性降低。
m <- prophet(df, changepoint.prior.scale = 0.001)
forecast <- predict(m, future)
plot(m, forecast)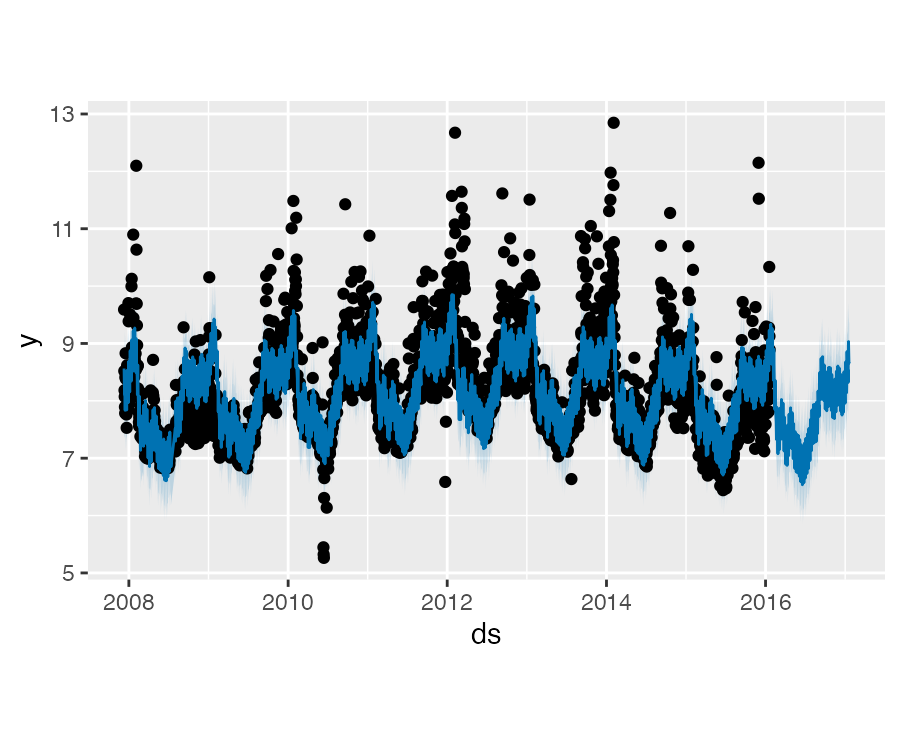
Prophet 趋势突变点
通过参数 changepoints 可以手动指定突变点而不是自动检测。
m <- prophet(df, changepoints = c("2014-01-01"))
forecast <- predict(m, future)
plot(m, forecast)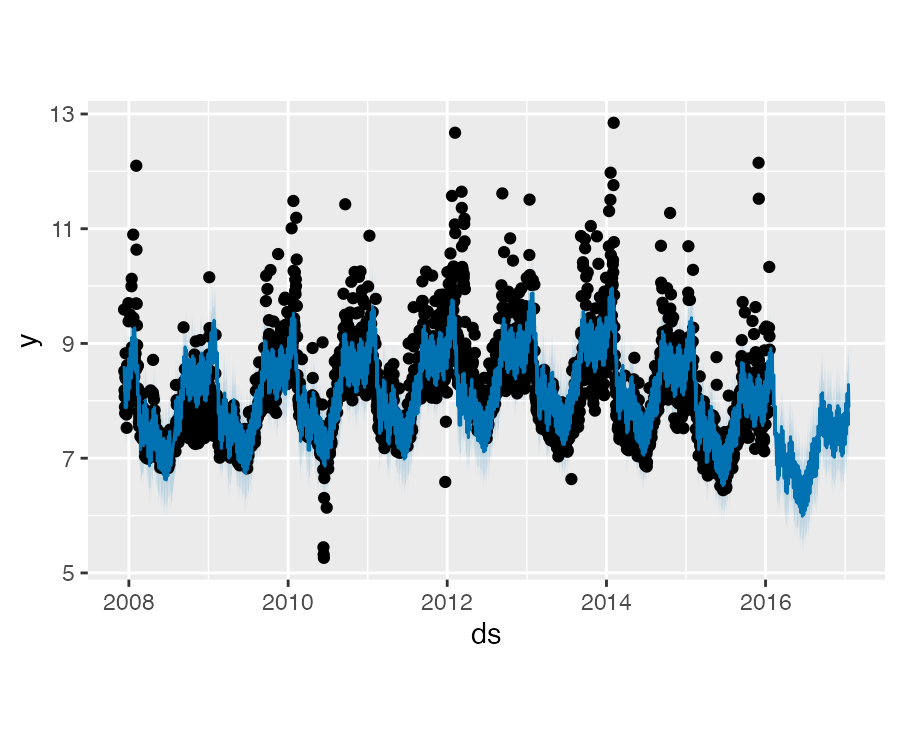
Prophet 季节性和节假日效应
在组成部分图中,如右图所示,也可以看到节假日效应。可以发现,在决赛日期附近有一个穿透,而在超级碗日期时穿透则更为明显。
prophet_plot_components(m, forecast)可以利用 plot_forecast_component() 函数绘制各个组成部分,例如 plot_forecast_component(m, forecast, "superbowl") 仅绘制超级碗节假日部分。
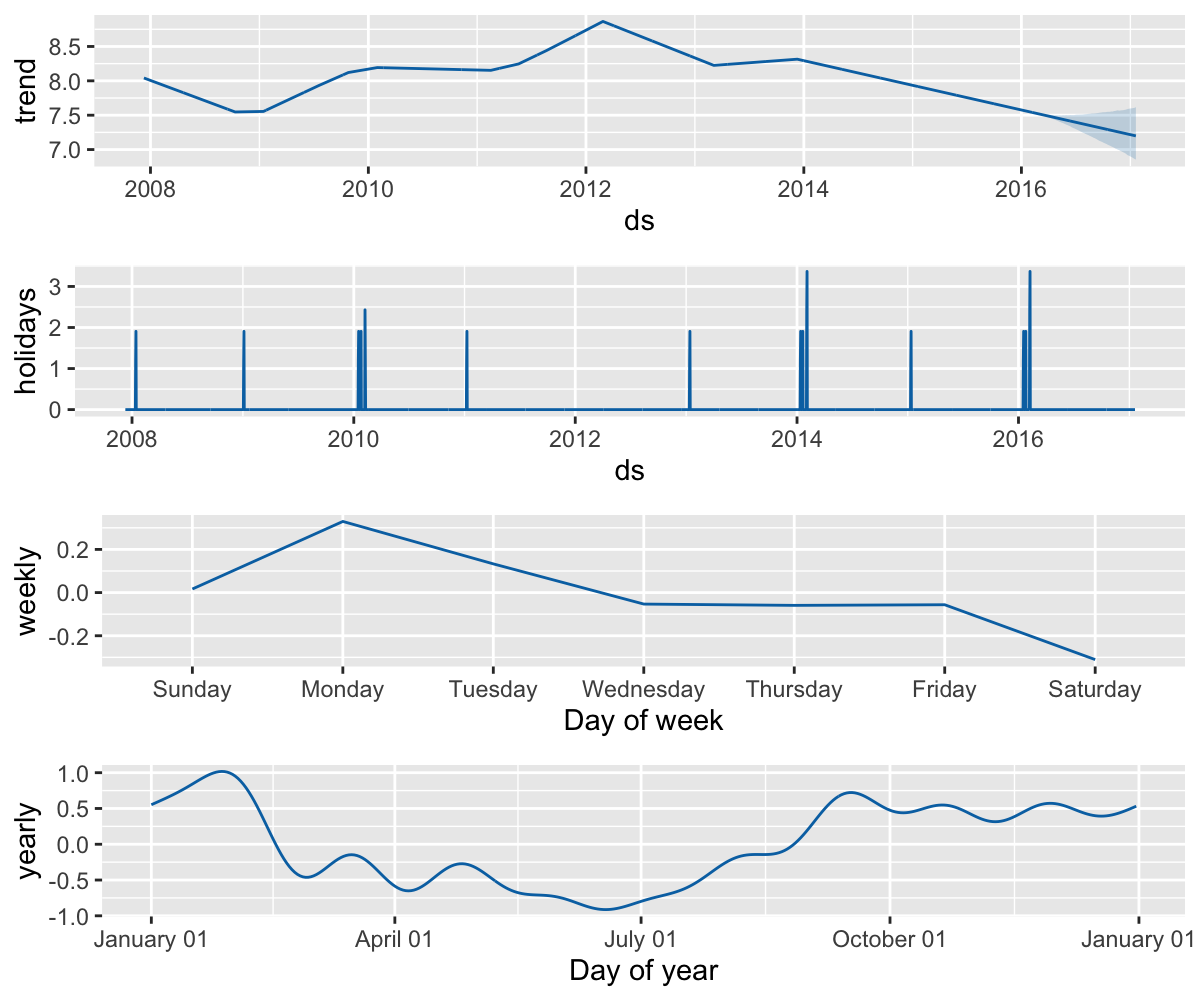
Prophet 季节性和节假日效应
每个国家中的节假日由 holidays 扩展包提供,可用的国家及其名称详见这里。除此之外,Prophet 还提供了以下国家的节假日:巴西(BR),印度尼西亚(ID),印度(IN),马来西亚(MY),越南(VN),泰国(TH),菲律宾(PH),土耳其( TU),巴基斯坦(PK),孟加拉国(BD),埃及(EG),中国(CN)和俄罗斯(RU)。
在 R 中,1995 至 2044 年的节假日数据保存在包的 data-raw/tmp_holidays.csv 文件中。如上所述,国家地区级别的节假日也将展现在组成部分图中:
forecast <- predict(m, future)
prophet_plot_components(m, forecast)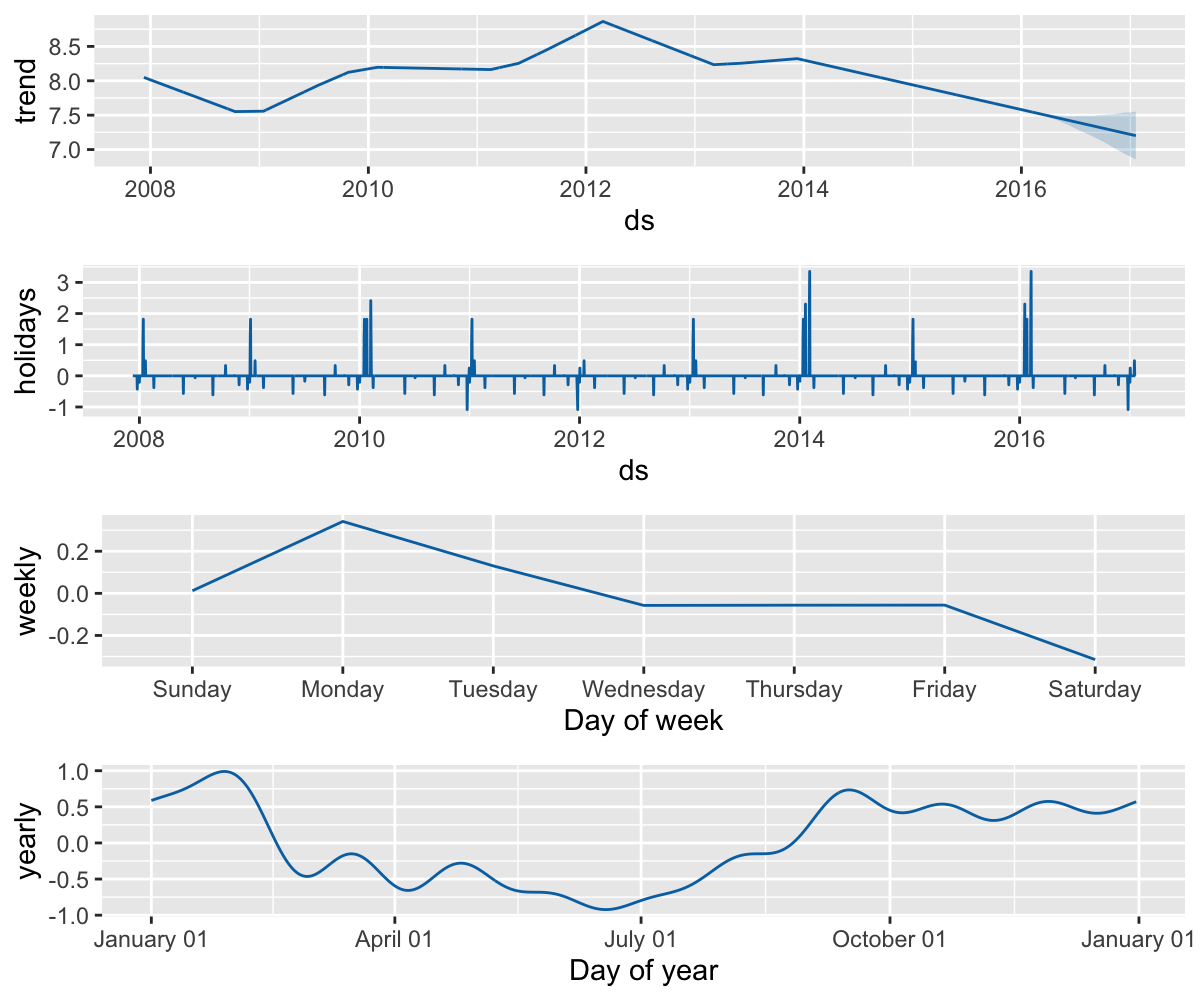
Prophet 季节性和节假日效应
季节性是利用一个 Partial Fourier Sum 进行估计的,具体计算过程详见论文。Wikipedia 中的这张图描述了一个 Partial Fourier Sum 是如何逼近一个任意的周期性信号的。Partial Sum 中项的个数决定了季节性变化的快慢。年度季节性的默认傅立叶阶数为 10:
{kind=link}
m <- prophet(df)
prophet:::plot_yearly(m)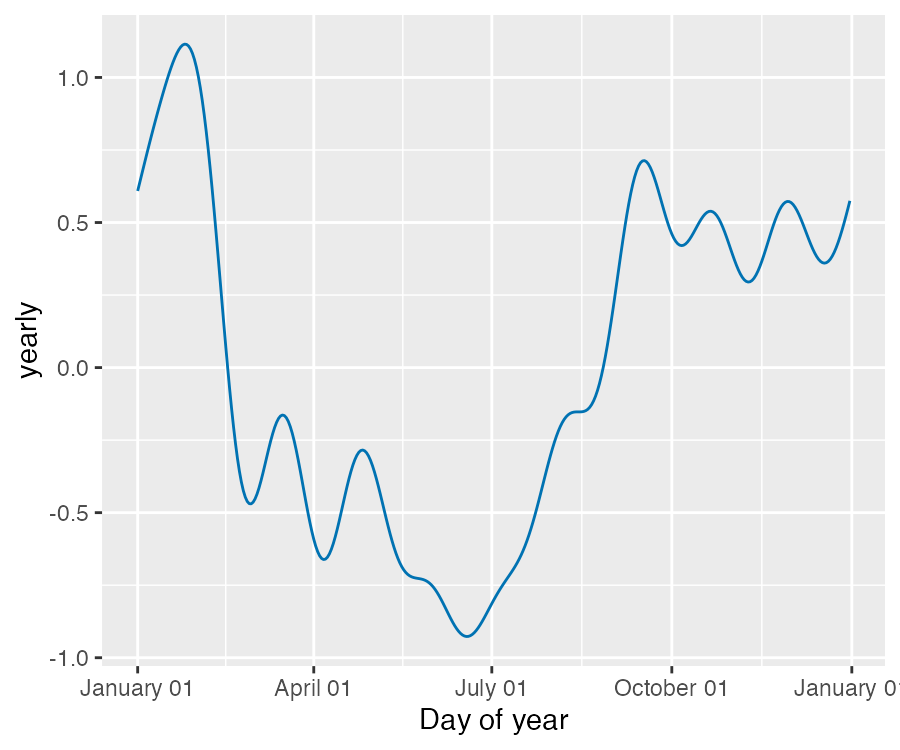
Prophet 季节性和节假日效应
通常情况下默认值是合适的,但当季节性需要拟合更高偏离的变化时则可以增加这个参数值。当增加到 20 时:
m <- prophet(df, yearly.seasonality = 20)
prophet:::plot_yearly(m)增加傅立叶项的个数可以使季节性拟合更快的变化周期,但同时也可能导致过拟合。 \(N\) 个傅立叶项对应到周期建模中 \(2N\) 个变量。

Prophet 季节性和节假日效应
如果时间序列长度在两个周期以上,Prophet 将会默认拟合周和年的季节性,对于日以下尺度时间序列会拟合日季节性。利用 add_seasonality() 方法可以添加其他季节性,例如:月,季度,小时尺度的季节性。
该函数的参数分别为:季节性名称,以天为单位的季节性周期,以及季节性傅立叶阶数。默认情况下,Prophet 对于周季节性使用傅立叶阶数为 3,对于年季节性使用傅立叶阶数为 10。
m <- prophet(weekly.seasonality = FALSE)
m <- add_seasonality(
m, name = "monthly", period = 30.5, fourier.order = 5)
m <- fit.prophet(m, df)
forecast <- predict(m, future)
prophet_plot_components(m, forecast)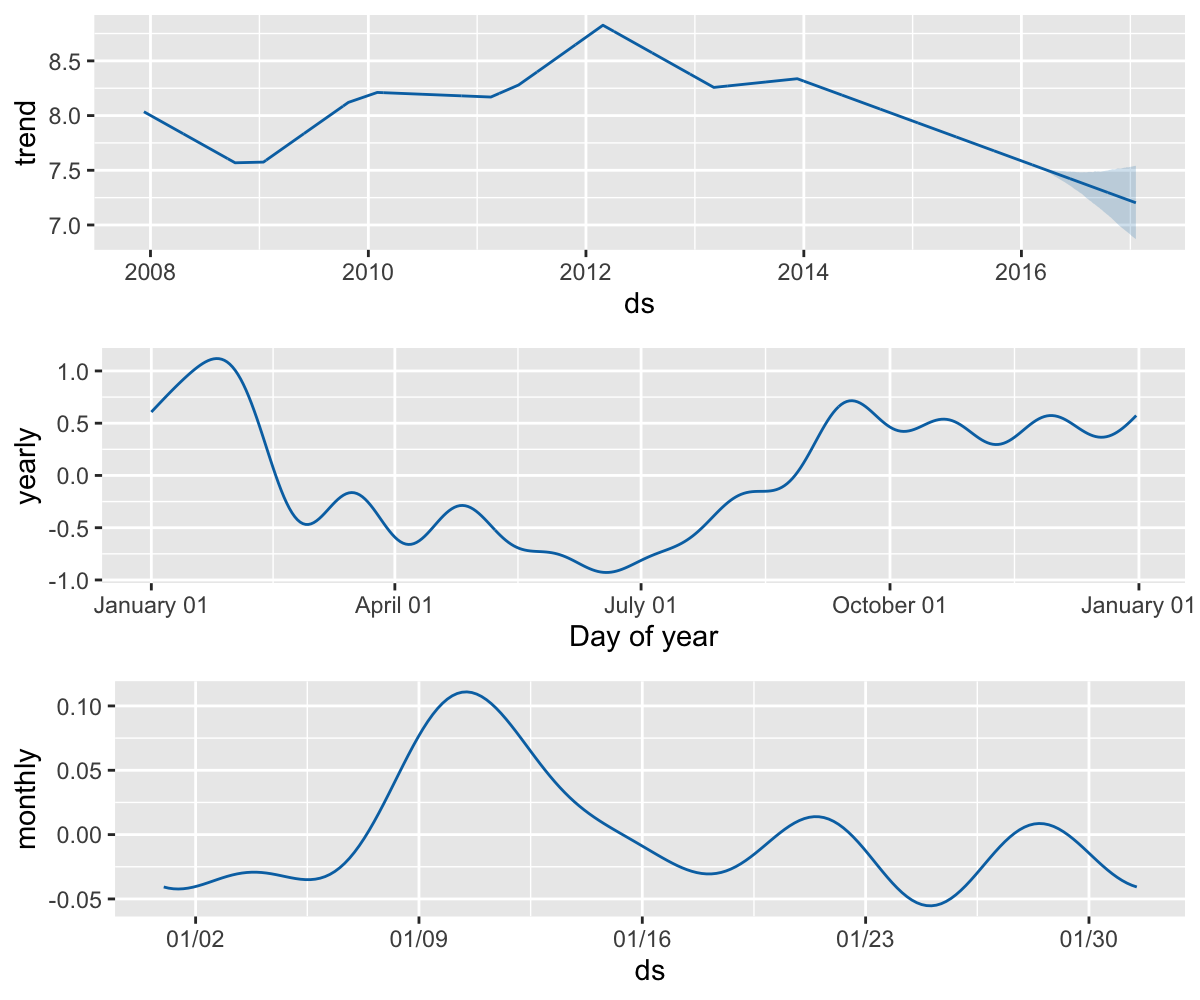
Prophet 季节性和节假日效应
两个季节性均可以从组成部分图中显示。可以看出,在每周日均进行比赛的赛季,周日和周一会有大量的增长,而在非赛季则完全没有。
m <- prophet(weekly.seasonality = FALSE)
m <- add_seasonality(
m, name = "weekly_on_season", period = 7,
fourier.order = 3, condition.name = "on_season")
m <- add_seasonality(
m, name = "weekly_off_season", period = 7,
fourier.order = 3, condition.name = "off_season")
m <- fit.prophet(m, df)
future$on_season <- is_nfl_season(future$ds)
future$off_season <- !is_nfl_season(future$ds)
forecast <- predict(m, future)
prophet_plot_components(m, forecast)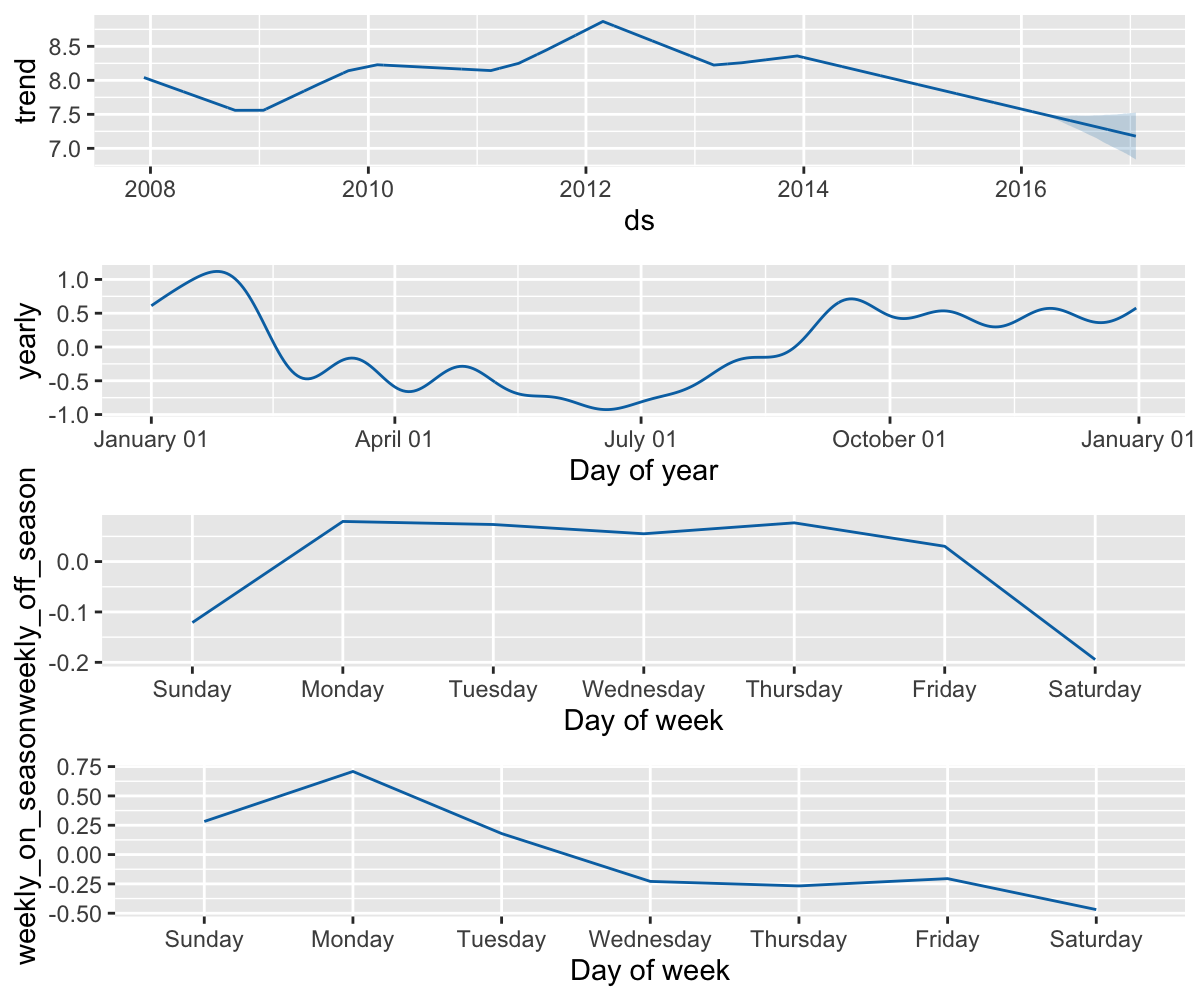
Prophet 季节性和节假日效应
df$nfl_sunday <- nfl_sunday(df$ds)
m <- prophet()
m <- add_regressor(m, "nfl_sunday")
m <- fit.prophet(m, df)
future$nfl_sunday <- nfl_sunday(future$ds)
forecast <- predict(m, future)
prophet_plot_components(m, forecast)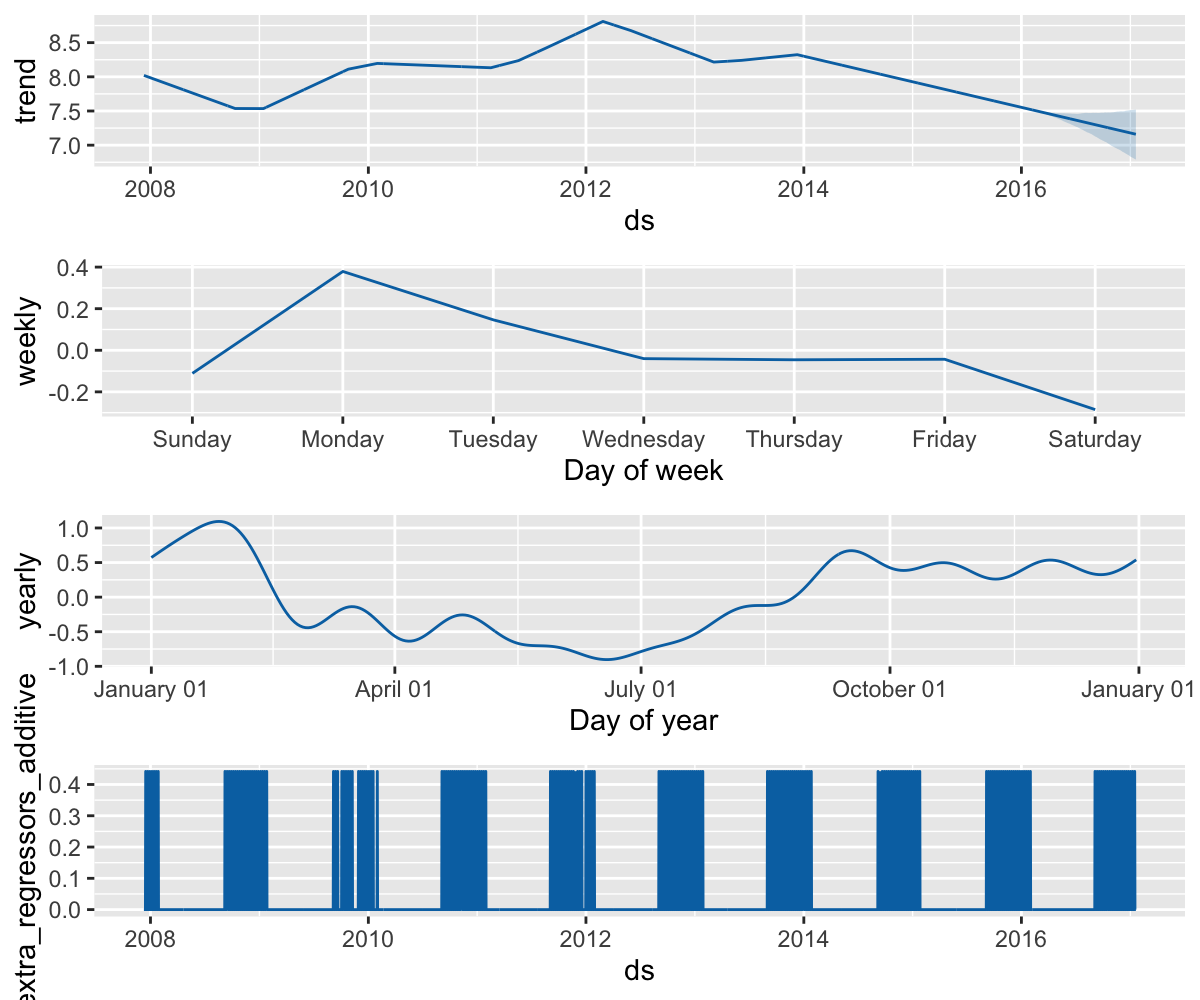
Prophet 乘法型季节性
默认情况下,Prophet 拟合的是加法型季节性,也就是说将季节性加到趋势中获取预测。如下示例为一个加法型季节性不适用的航空旅客数量的时间序列:
df <- read.csv("data/example_air_passengers.csv")
m <- prophet(df)
future <- make_future_dataframe(m, 50, freq = "m")
forecast <- predict(m, future)
plot(m, forecast)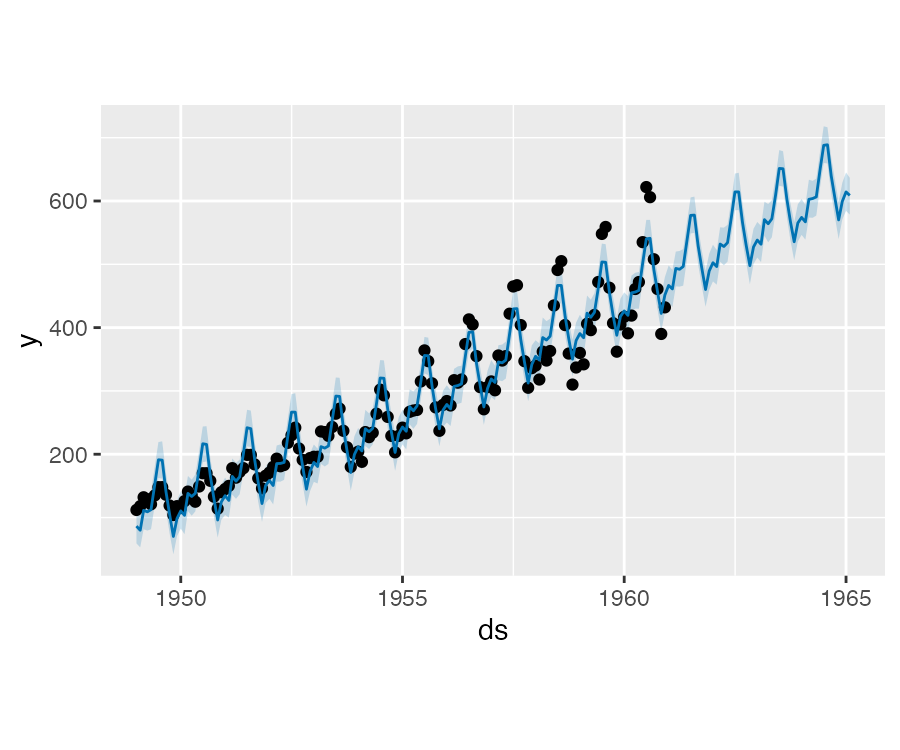
Prophet 乘法型季节性
该时间序列具有清晰的年周期性,但预测中的季节性在开始处太大,在结尾处太小。在这个时间序列中,季节型并不像 Prophet 所设想的一样是一个常数加法因子,而是随着趋势增长,这就是乘法型季节性。
Prophet 可以通过设置 seasonality.mode= "multiplicative" 构建乘法型季节性模型:
m <- prophet(
df, seasonality.mode = "multiplicative")
forecast <- predict(m, future)
plot(m, forecast)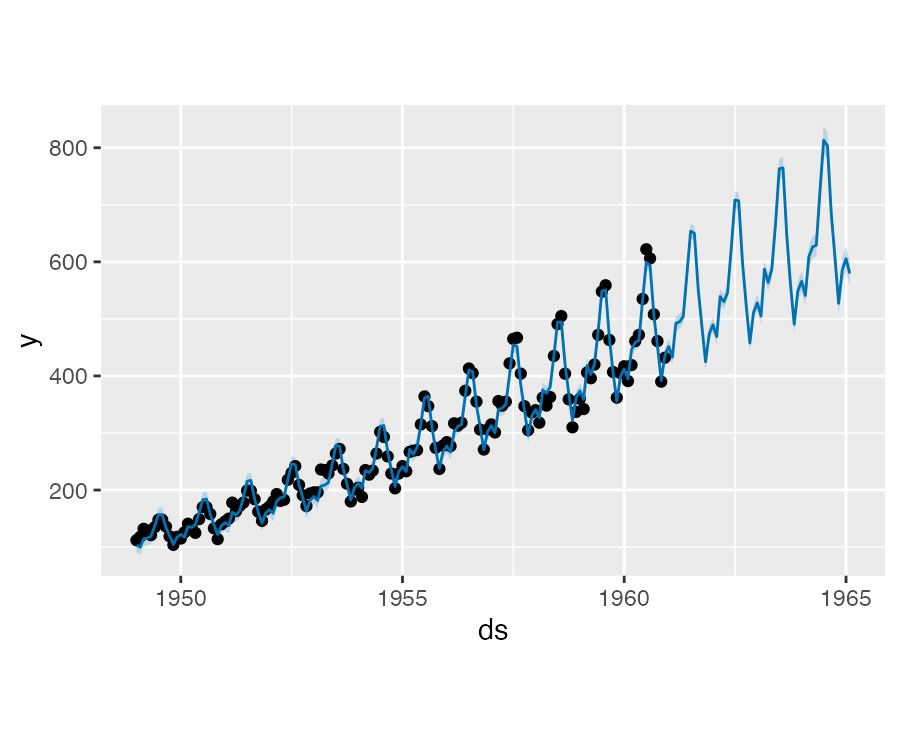
Prophet 乘法型季节性
季节性将在组成部分图中展现为趋势的百分比:
prophet_plot_components(m, forecast)通过设置 seasonality.mode="multiplicative",节假日效应也可以建模为乘法模型。任何添加的季节性或回归变量也会使用相同类型的模型,但其也可以单独传入自己所需的类型。例如,下面的示例中设置了一个外部的乘法型季节性模型,但其包括了一个加法型季度季节性因子和一个加法型回归变量:
m <- prophet(seasonality.mode = "multiplicative")
m <- add_seasonality(
m, "quarterly", period = 91.25,
fourier.order = 8, mode = "additive")
m <- add_regressor(
m, "regressor", mode = "additive")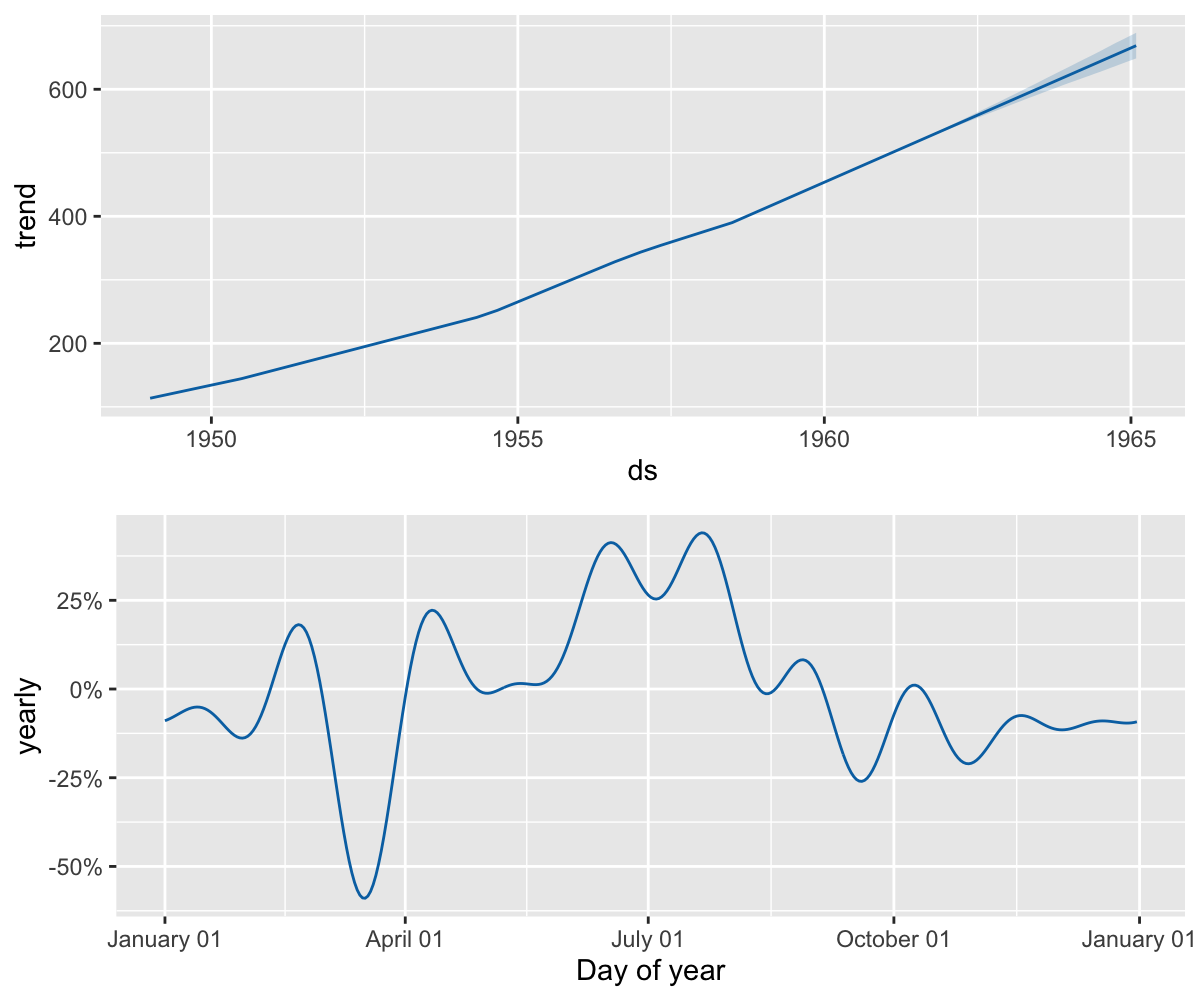
Prophet 预测区间
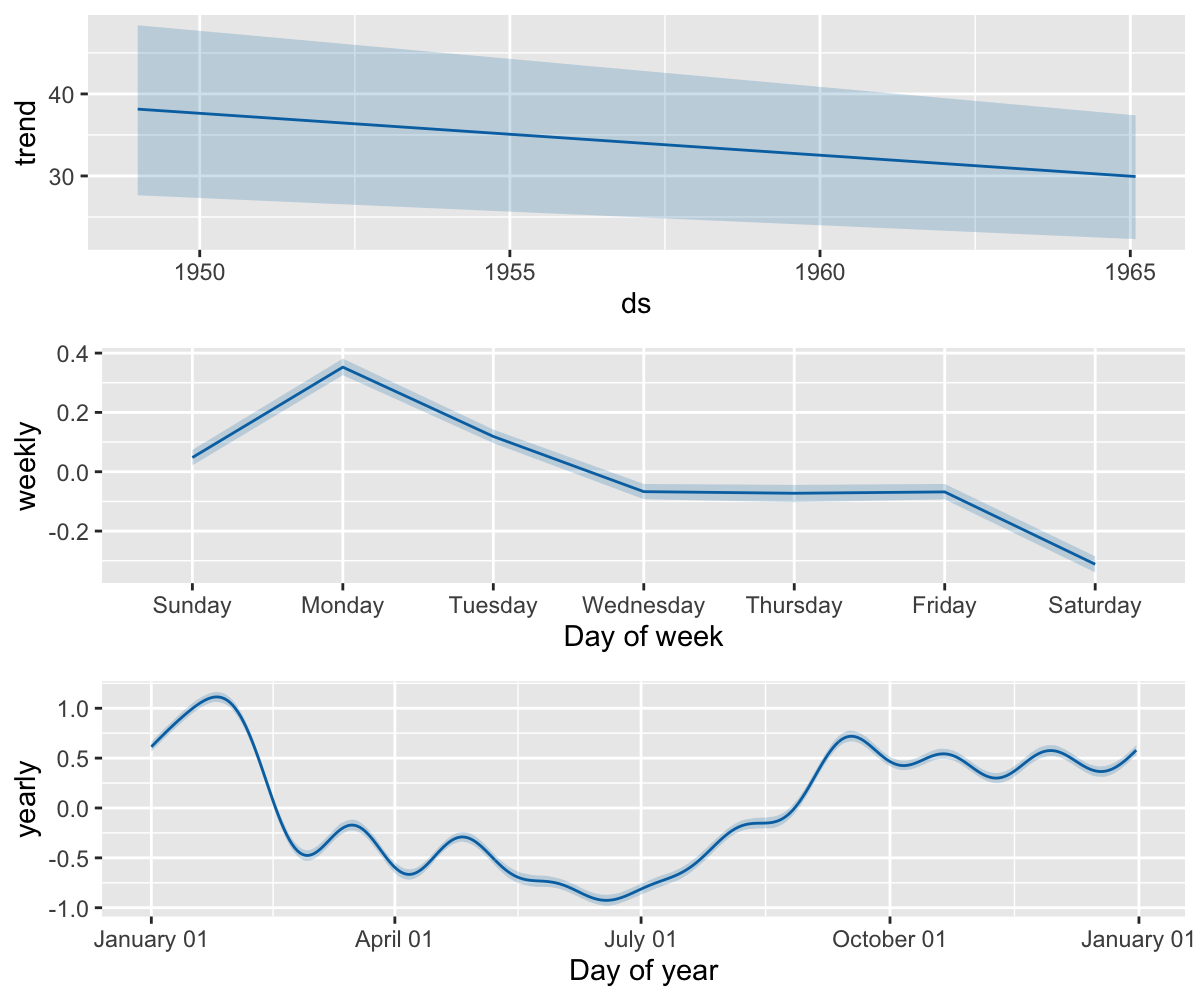
默认情况下, Prophet 只会返回趋势和观测值噪声中的不确定性。为了获取季节效应的不确定性,必须进行完整的贝叶斯采样。这可以通过设置 mcmc.samples 参数(默认值为 0 )来实现。以 Peyton Manning 数据为例:
m <- prophet(df, mcmc.samples = 300)
forecast <- predict(m, future)
prophet_plot_components(m, forecast)这将采用 MCMC 采样替代 MAP 估计,并可能需要更长的时间,具体取决于观测的数据量。如果进行了完全采样,就会在组成部分图中看到季节性的不确定性。利用 m.predictive_samples(future) 方法可以获得原始的后验预测样本。
Prophet 异常值
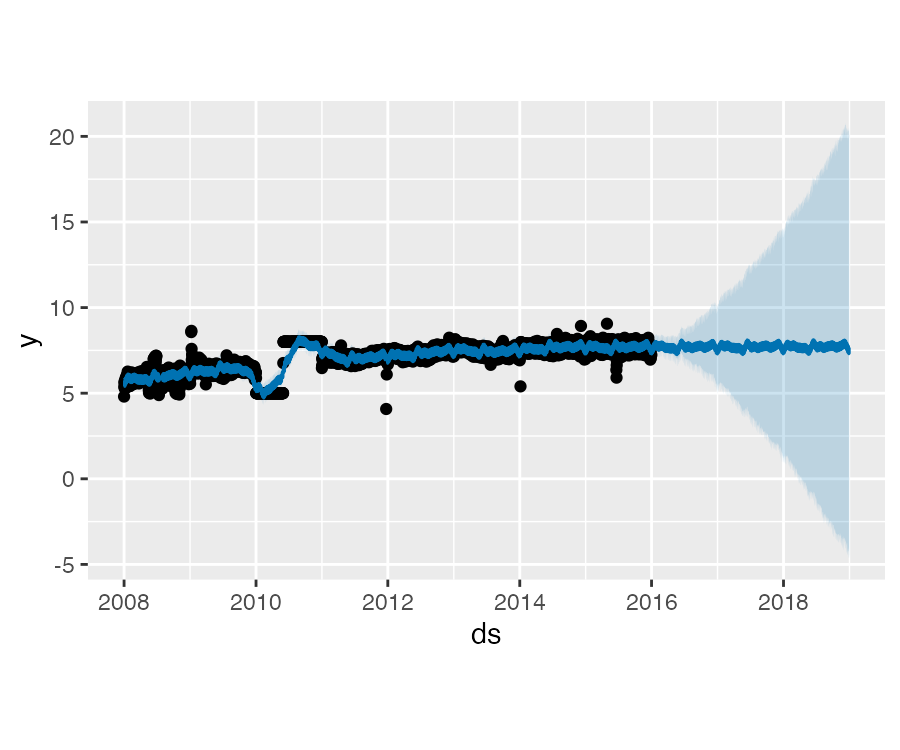
异常值主要通过两种方式影响 Prophet 预测结果。下面我们使用之前使用过的 R 语言维基百科主页对数访问量的数据来建模预测,但其中包含了大量错误数据:
df <- read_csv(
"data/example_wp_log_R_outliers1.csv")
m <- prophet(df)
future <- make_future_dataframe(m, periods = 1096)
forecast <- predict(m, future)
plot(m, forecast)趋势预测似乎是合理的,但预测区间过宽。Prophet 可以处理历史数据中的异常值,但只能通过拟合趋势变化来解决。不确定性模型会以相似的幅度预计未来的趋势变化。
Prophet 异常值
处理异常值的最佳方法就是移除他们,Prophet 是能够处理缺失数据的。如果在历史数据中某些行的值为空(NA),但在待预测数据中保留有这个日期,那么 Prophet 会对这些值进行预测。
outliers <- (
as.Date(df$ds) > as.Date("2010-01-01")
& as.Date(df$ds) < as.Date("2011-01-01"))
df$y[outliers] <- NA
m <- prophet(df)
forecast <- predict(m, future)
plot(m, forecast)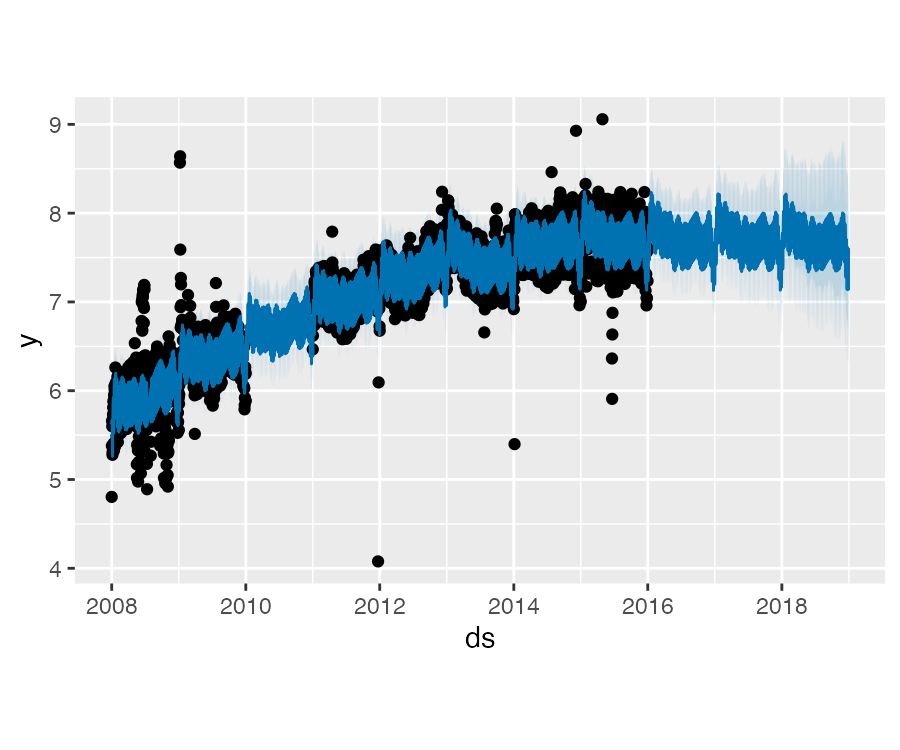
Prophet 异常值
上述这个示例中,异常值虽然影响了预测区间的估计,但却没有影响主要的预测结果 yhat。但实际情况并非都是如此,下面这个示例中在添加新的异常值后则影响了主要的预测结果:
df <- read_csv(
"data/example_wp_log_R_outliers2.csv")
m <- prophet(df)
future <- make_future_dataframe(m, periods = 1096)
forecast <- predict(m, future)
plot(m, forecast)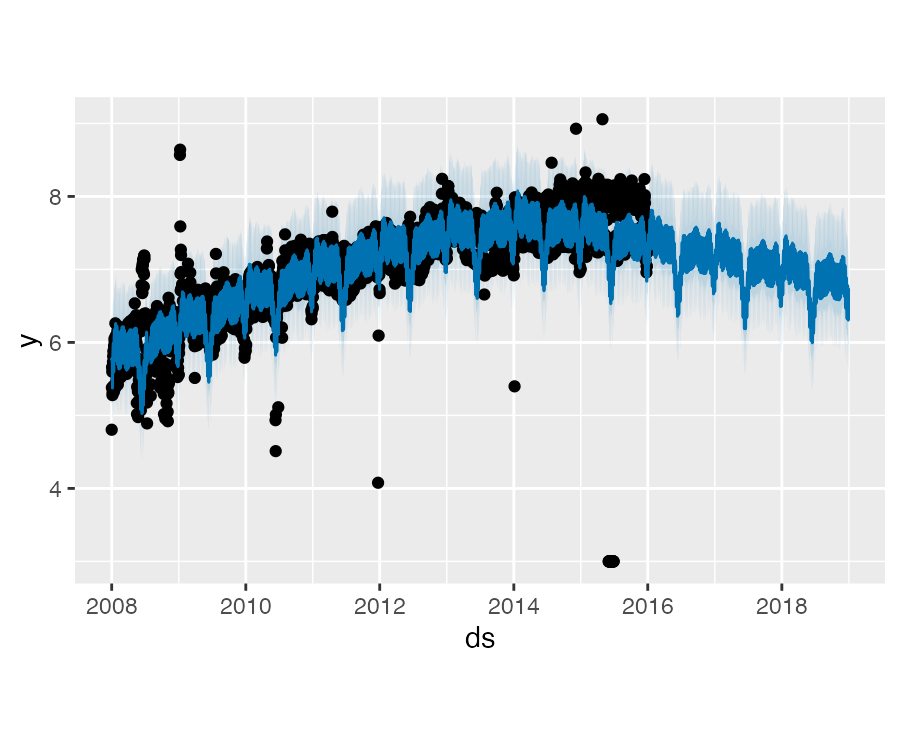
Prophet 异常值
下面这个示例中,在 2015 年 6 月份一组异常值破坏了季节性的估计,因此未来的预测值也受到了影响。同样,最好的解决方法就是移除这些异常值:
outliers <- (
as.Date(df$ds) > as.Date("2015-06-01")
& as.Date(df$ds) < as.Date("2015-06-30"))
df$y[outliers] <- NA
m <- prophet(df)
forecast <- predict(m, future)
plot(m, forecast)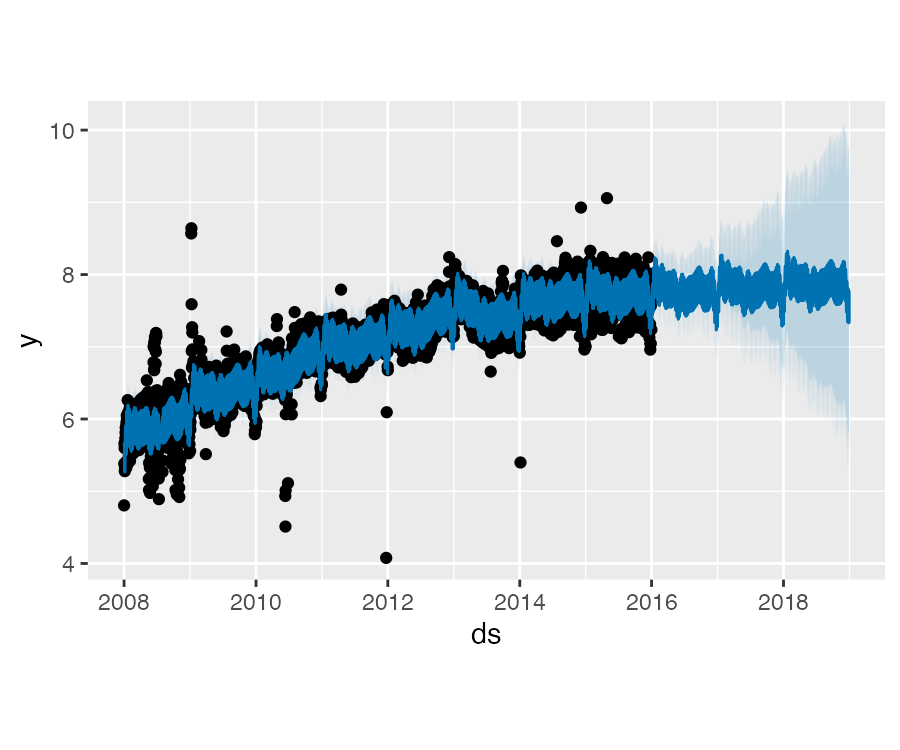
Prophet 非日尺度数据
通过在数据框中添加带有时间戳的 ds 列可以让 Prophet 预测非日尺度的时间序列。时间戳的格式应为 YYYY-MM-DD HH:MM:SS。当使用非日尺度的数据时,模型会自动拟合日尺度的季节性。下面示例为一个以 5 分钟为间隔的 Yosemite 地区每日的气温数据:
df <- read.csv("data/example_yosemite_temps.csv")
m <- prophet(df, changepoint.prior.scale = 0.01)
future <- make_future_dataframe(
m, periods = 300, freq = 60 * 60)
fcst <- predict(m, future)
plot(m, fcst)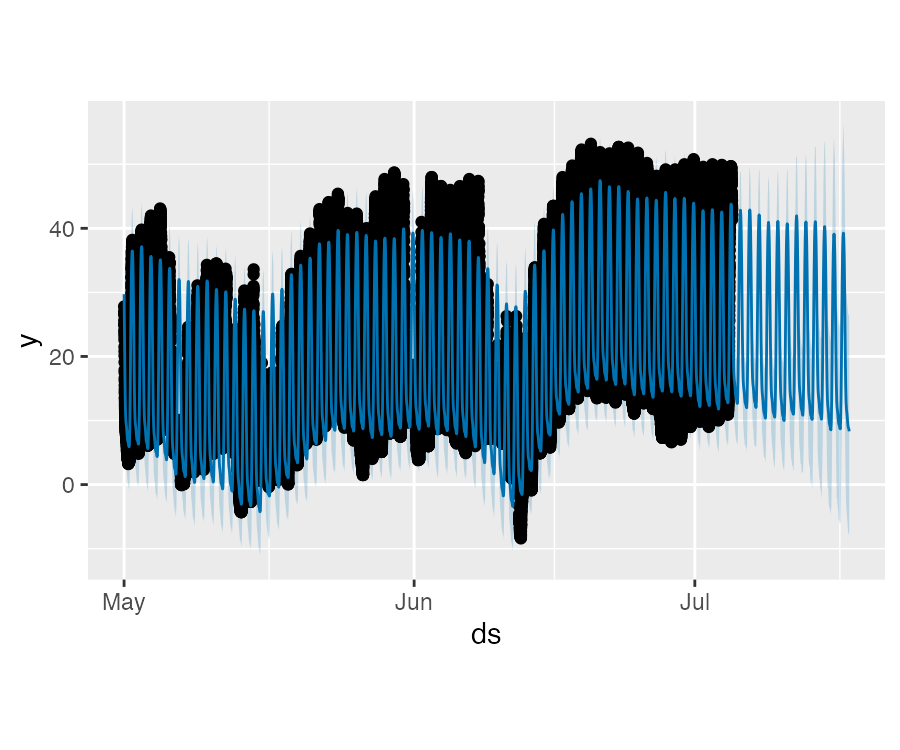
Prophet 非日尺度数据
日尺度的季节性将展示在组成部分图中:
prophet_plot_components(m, fcst)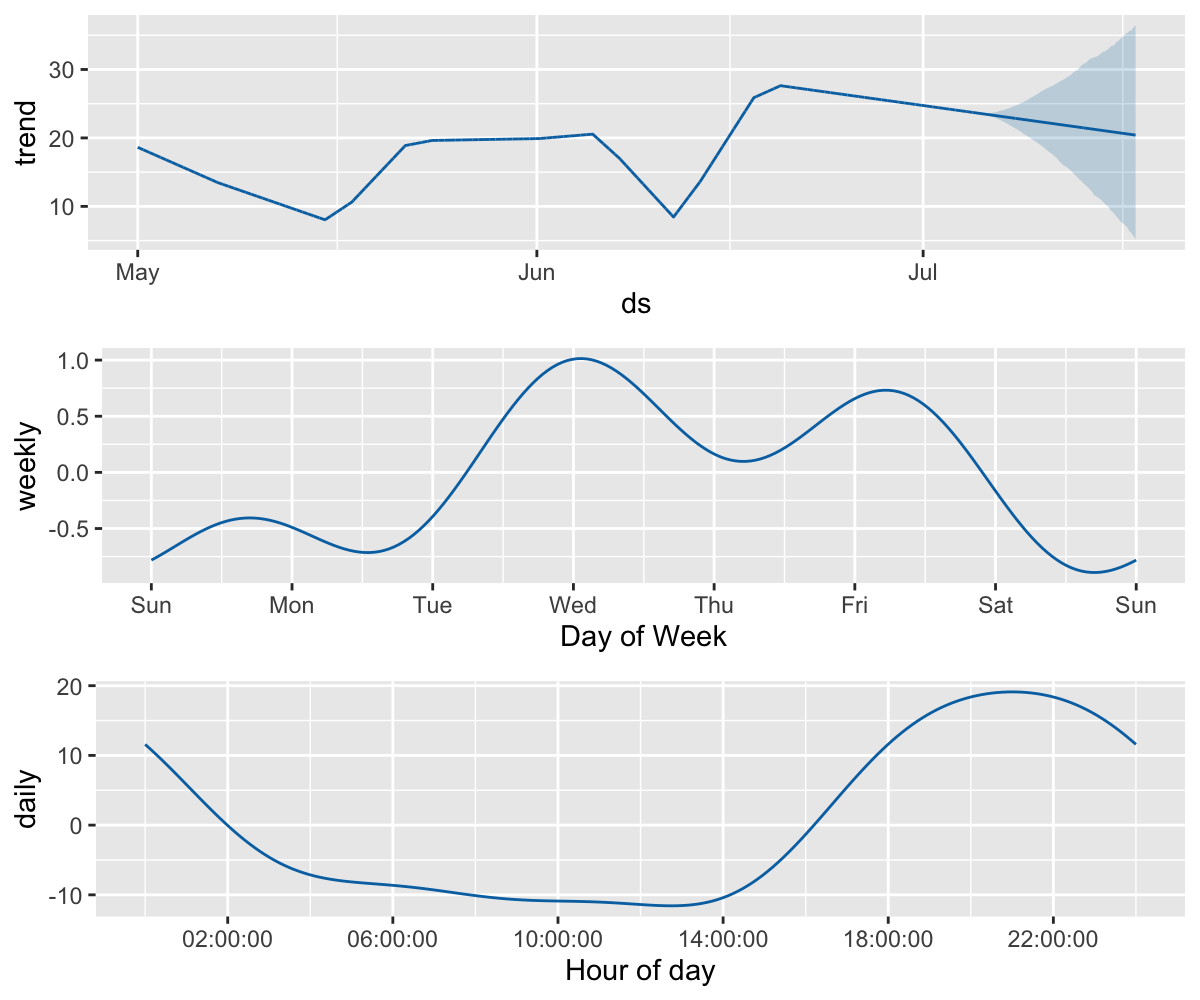
Prophet 非日尺度数据
假设上面的数据集只有 0 时至 6 时的观测值:
df2 <- df |>
mutate(ds = as.POSIXct(ds, tz = "GMT")) |>
filter(as.numeric(format(ds, "%H")) < 6)
m <- prophet(df2)
future <- make_future_dataframe(
m, periods = 300, freq = 60 * 60)
fcst <- predict(m, future)
plot(m, fcst)预测效果似乎很差,未来的波动要比历史数据中大得多。这里的问题是我们仅利用一天中的部分数据(0 时至 6 时)去拟合一整天,因此日尺度的季节性对于一天中剩下的时段是未被很好的估计的。
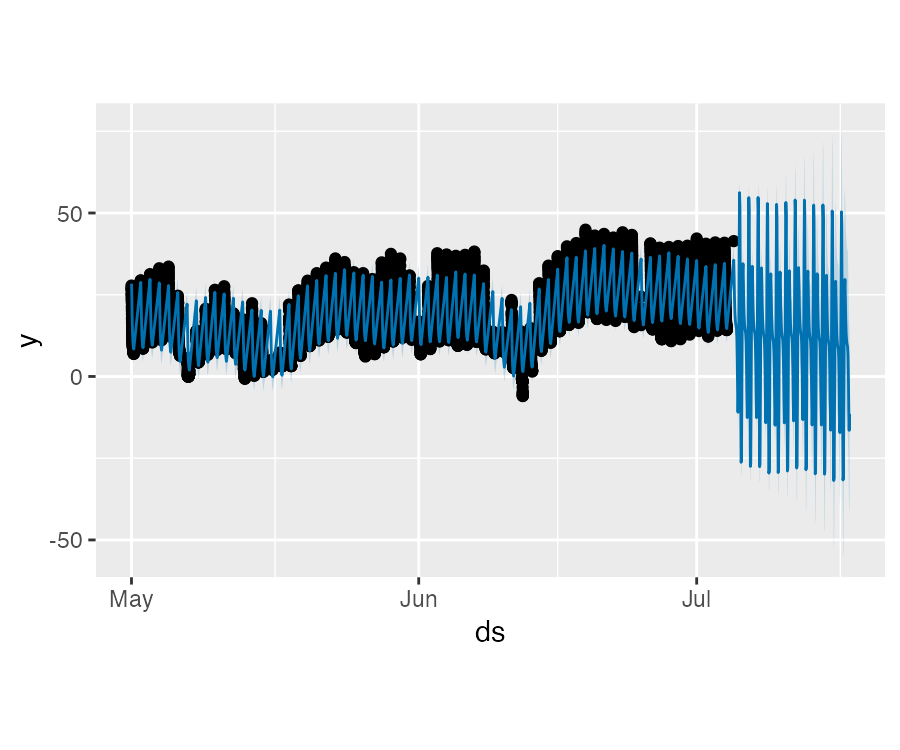
Prophet 非日尺度数据
解决的方案是仅对具有历史数据的时间窗口进行预测,本例中我们需要将待预测的数据也限制在 0 时至 6 时:
future2 <- future |>
filter(as.numeric(format(ds, "%H")) < 6)
fcst <- predict(m, future2)
plot(m, fcst)对于具有规则性间隔的其他数据也适用本原则。例如:如果历史数据仅包含工作日,那么待预测数据也需要仅包含工作日,因为周季节性未对周末进行很好的估计。
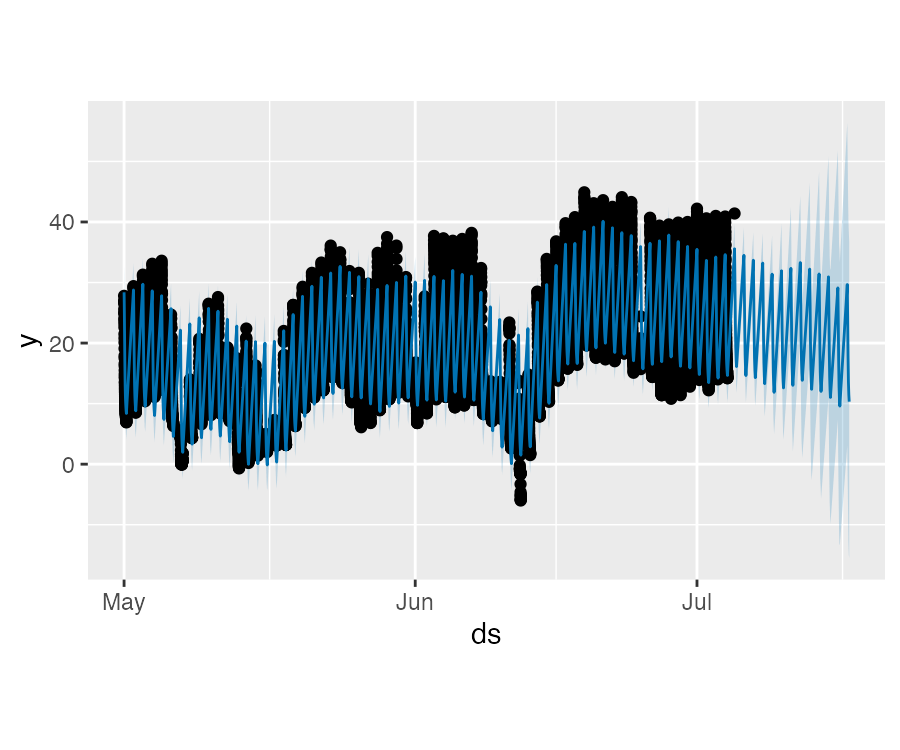
Prophet 非日尺度数据
利用 Prophet 可以拟合月尺度数据,但是如果用基于月尺度数据的模型预测未来每日的数据,往往会得到奇怪的结果。下面使用美国零售业的销量数据来预测未来 10 年的情况:
df <- read.csv("data/example_retail_sales.csv")
m <- prophet(
df, seasonality.mode = "multiplicative")
future <- make_future_dataframe(m, periods = 3652)
fcst <- predict(m, future)
plot(m, fcst)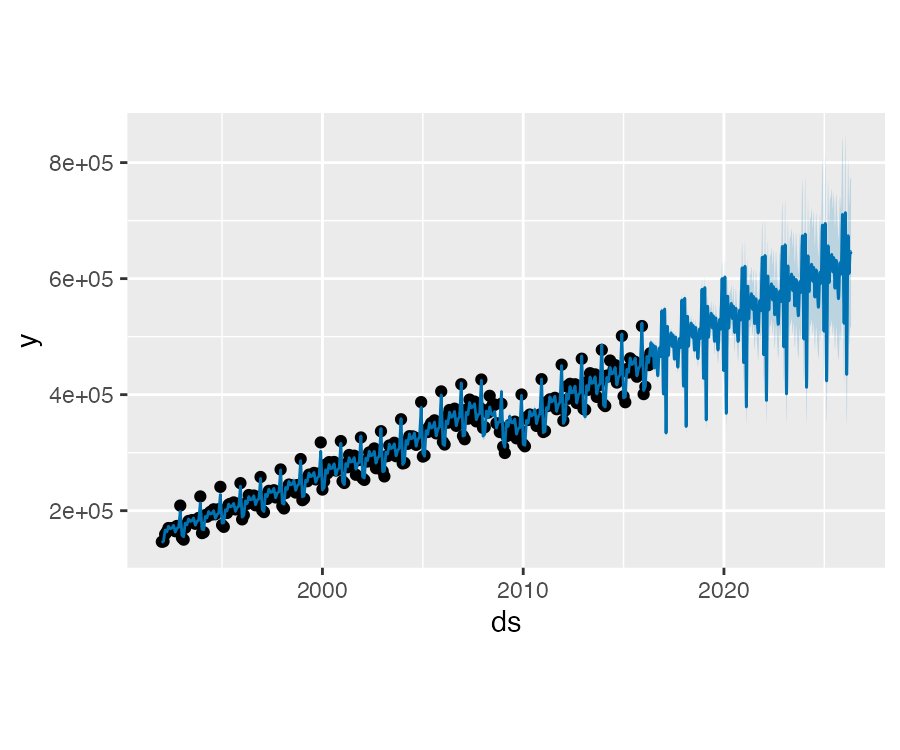
Prophet 非日尺度数据
这与上面的问题一样,数据集中有着规则的间隔,当拟合年尺度季节性时,它仅包含了每个月的前些数据,剩余日期的季节性因素是未识别且过拟合的。通过 MCMC 可以清楚的看到季节性中的不确定性:
m <- prophet(
df, seasonality.mode = "multiplicative",
mcmc.samples = 300)
fcst <- predict(m, future)
prophet_plot_components(m, fcst)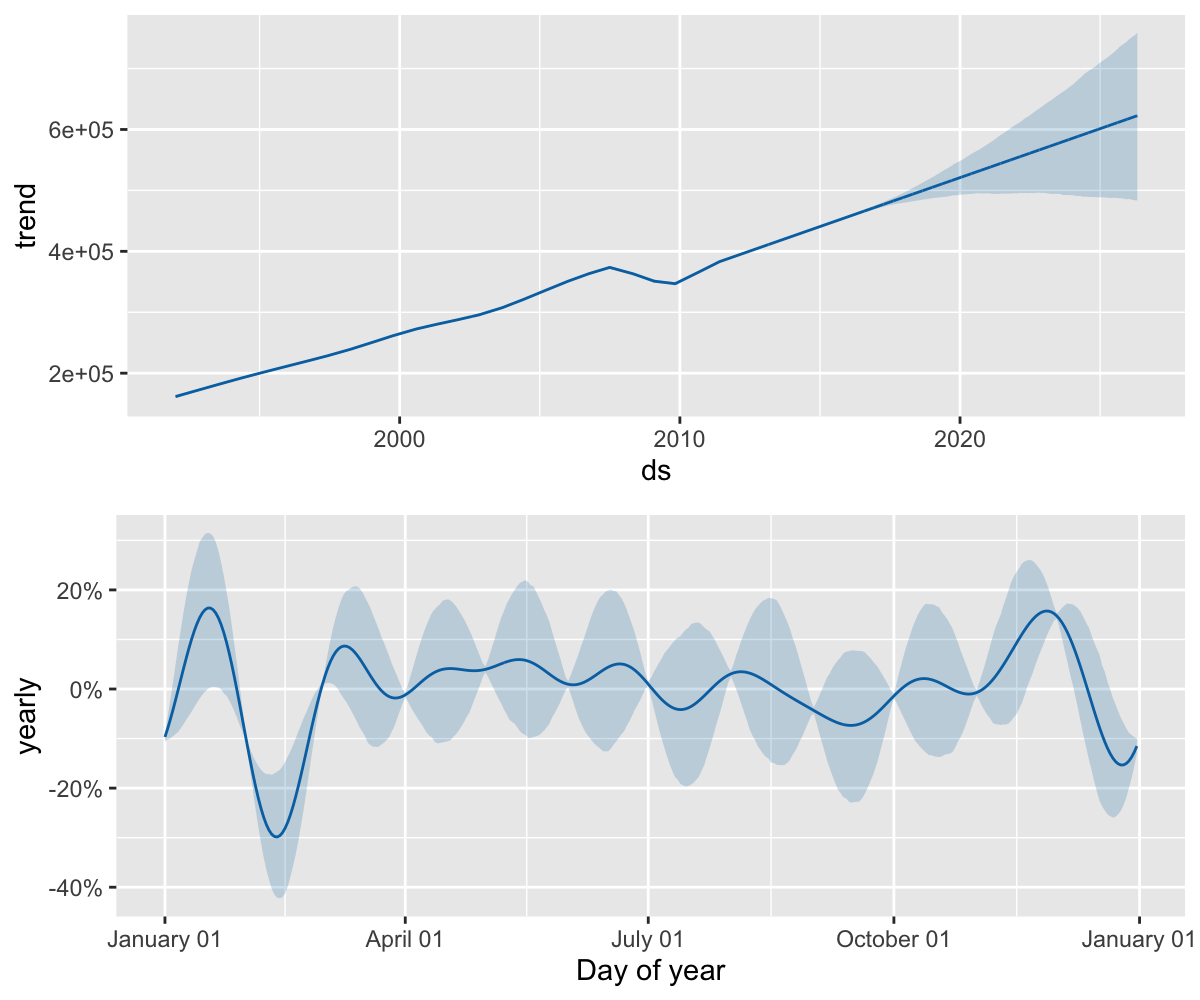
Prophet 非日尺度数据
在具有数据的每个月初,季节性具有较低的不确定性,但具有很高的后验方差。在利用 Prophet 拟合月尺度数据时,通过设置 make_future_dataframe() 中的 freq 可以进行月尺度的预测:
future <- make_future_dataframe(
m, periods = 120, freq = "month")
fcst <- predict(m, future)
plot(m, fcst)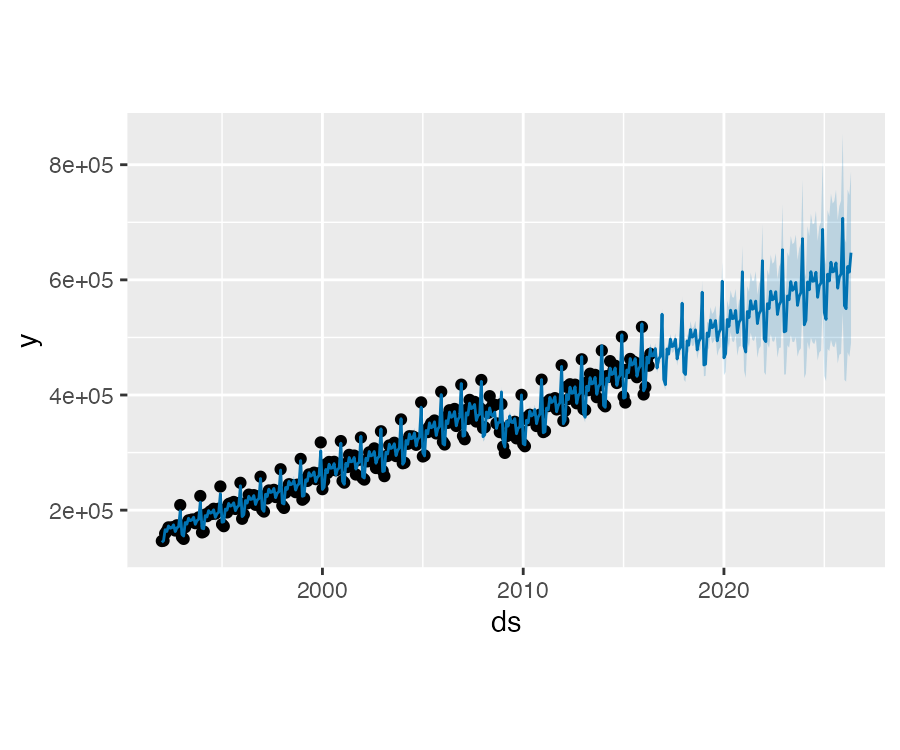
Prophet 性能评估
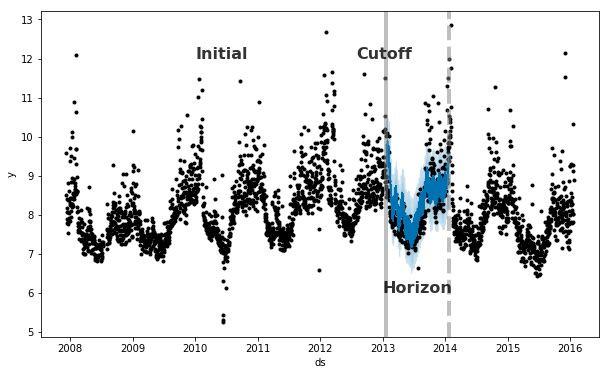
Prophet 提供了时间序列交叉检验的功能,用于利用历史数据来衡量预测误差。这是通过在历史数据中选择截止点来完成的,对于每个截止点仅使用之前的数据来拟合模型。之后可以将预测值和真实值进行比较。右图展示了一个 Peyton Manning 的模拟历史预测,其中模型利用历史数据的开始 5 年进行拟合,并对之后的一年进行了预测。
利用 cross_validation() 函数可以对一定范围的历史数据自动地进行交叉检验。通过指定预测时间范围(horizon),然后指定初始训练时间范围的大小(initial)和截止日期之前的时间间隔(period)。
默认情况下,初始训练时间范围为预测时间范围的 3 倍,截止点每半个预测周期一个。
Prophet 性能评估
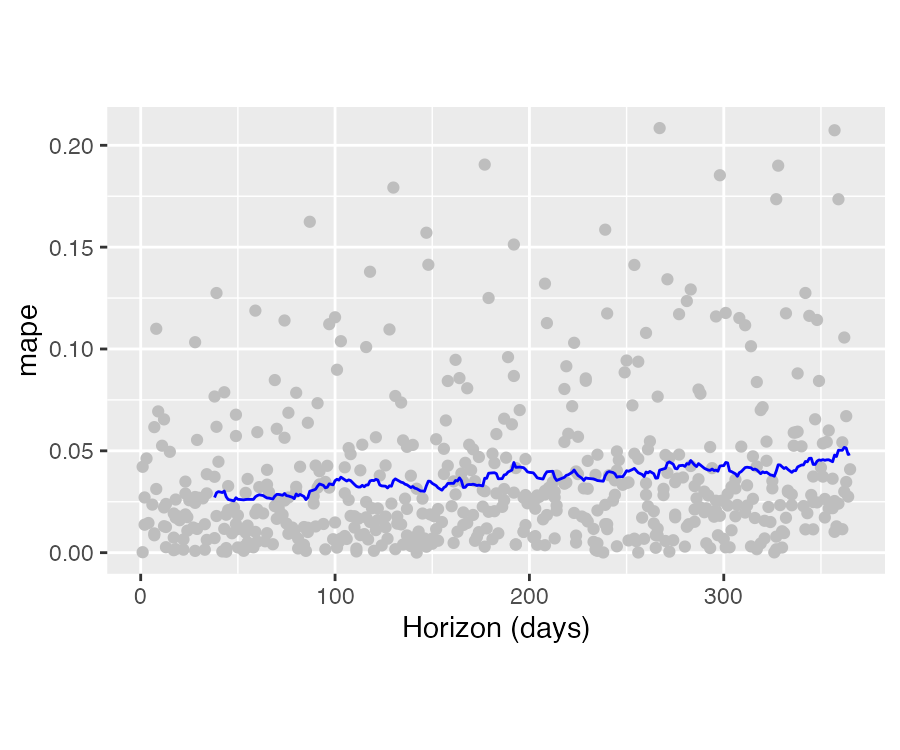
交叉检验的性能指标可以通过 plot_cross_validation_metric() 进行可视化。下面的示例中,圆点表示 df.cv 中每个预测的绝对百分比误差,蓝色的线为 MAPE,均值是利用滑动窗口中的圆点的值计算得到。从中可以看出,未来一个月的预测误差在 5% 左右,而一年后的误差会增加到 11% 左右。
plot_cross_validation_metric(df.cv, metric = "mape")增加 rolling_window 的值会让平均曲线更加平滑。初始范围应该足够长以保证捕获模型的所有组成部分,尤其是季节性和额外的回归变量。对于年季节性至少有一年的数据,对于周季节性至少有一周的数据,等等。
感谢倾听
本作品采用  授权
授权
版权所有 © 范叶亮 Leo Van