kmeans(x, centers, iter.max = 10, nstart = 1, algorithm = c("Hartigan-Wong", "Lloyd", "Forgy", "MacQueen"),
trace = FALSE)聚类算法
Clustering Algorithms
K-means
当 \(p = 1\) 时,称之为曼哈顿距离(Manhattan distance)或出租车距离:
\[ dist_{man}\left(x, y\right) = \sum_{i=1}^{n} |x_i - y_i| \]
当 \(p = 2\) 时,称之为欧式距离(Euclidean distance):
\[ dist_{ed}\left(x, y\right) = \sqrt{\sum_{i=1}^{n} \left(x_i - y_i\right)^2} \]
曼哈顿距离和欧式距离直观比较如图所示:

K-means
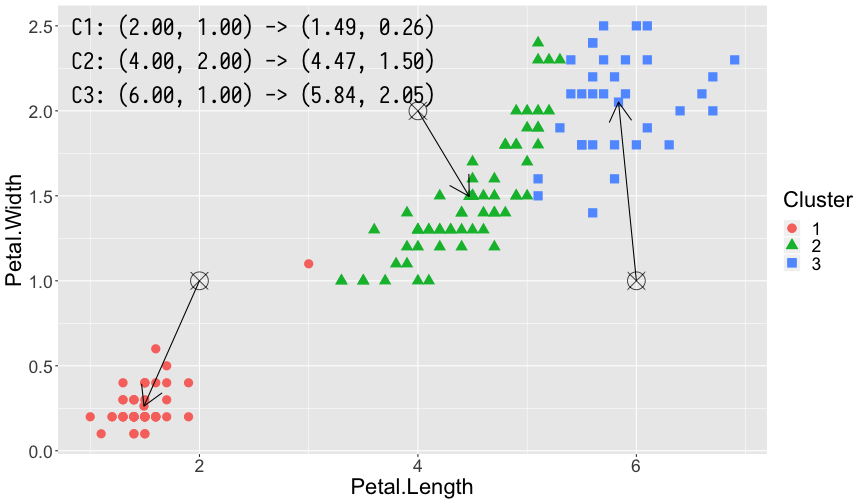
K-means
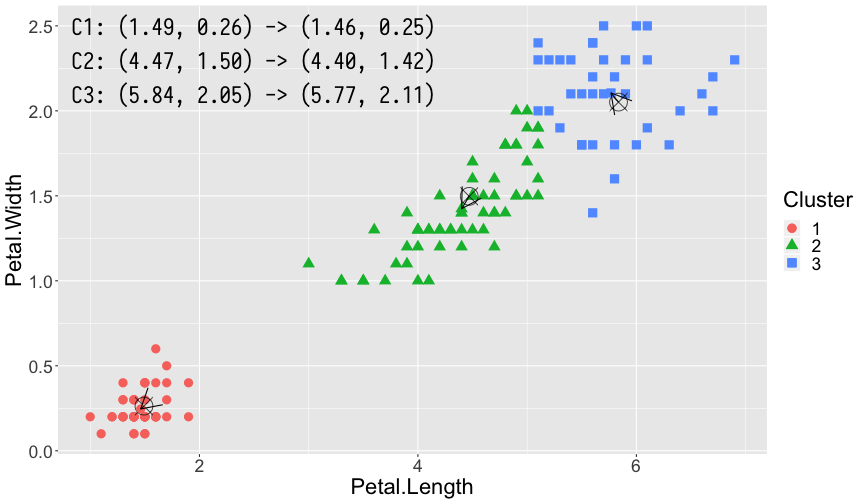
K-means
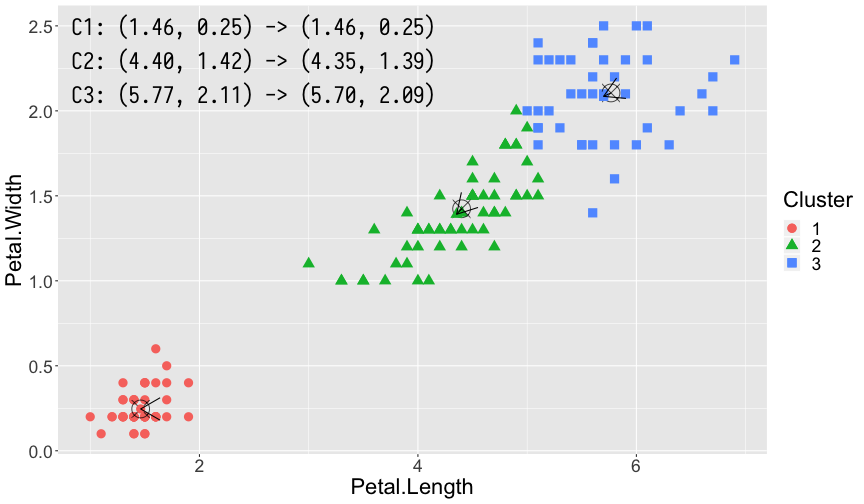
K-means
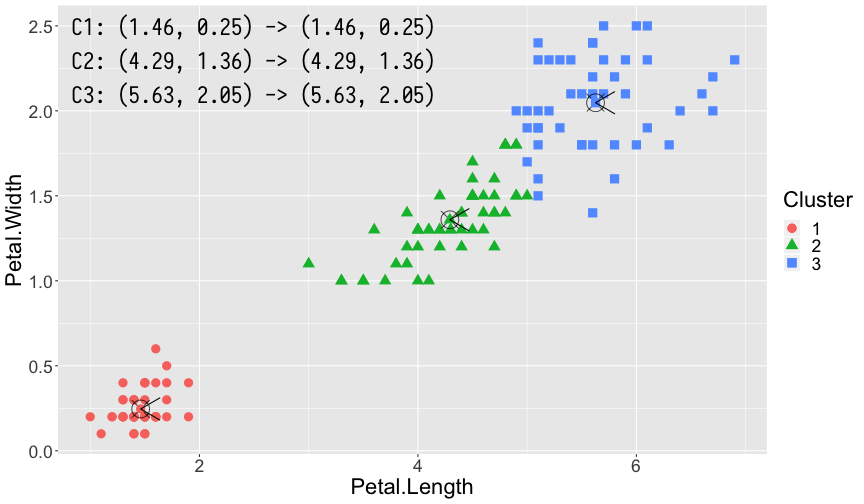
K-means
iris_ <- iris[, 3:4]
iris_kmeans <- kmeans(iris_, 3, nstart = 25)
iris_res <- dplyr::bind_cols(
iris_,
Cluster = as.factor(iris_kmeans$cluster)
)
ggplot(iris_res, aes(Petal.Length, Petal.Width)) +
geom_point(aes(color = Cluster, shape = Cluster))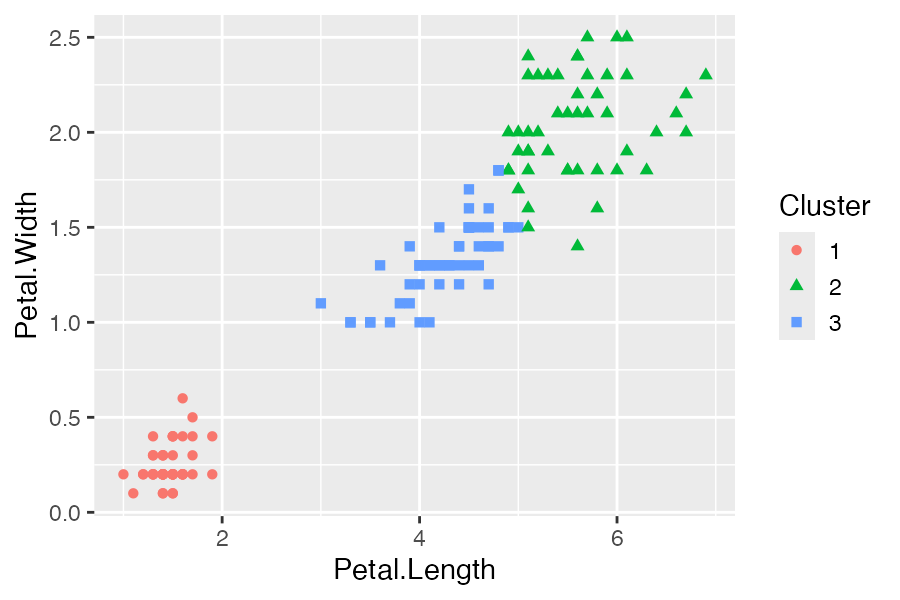
K-means
factoextra::fviz_cluster(iris_kmeans, data=iris_, geom=c("point"))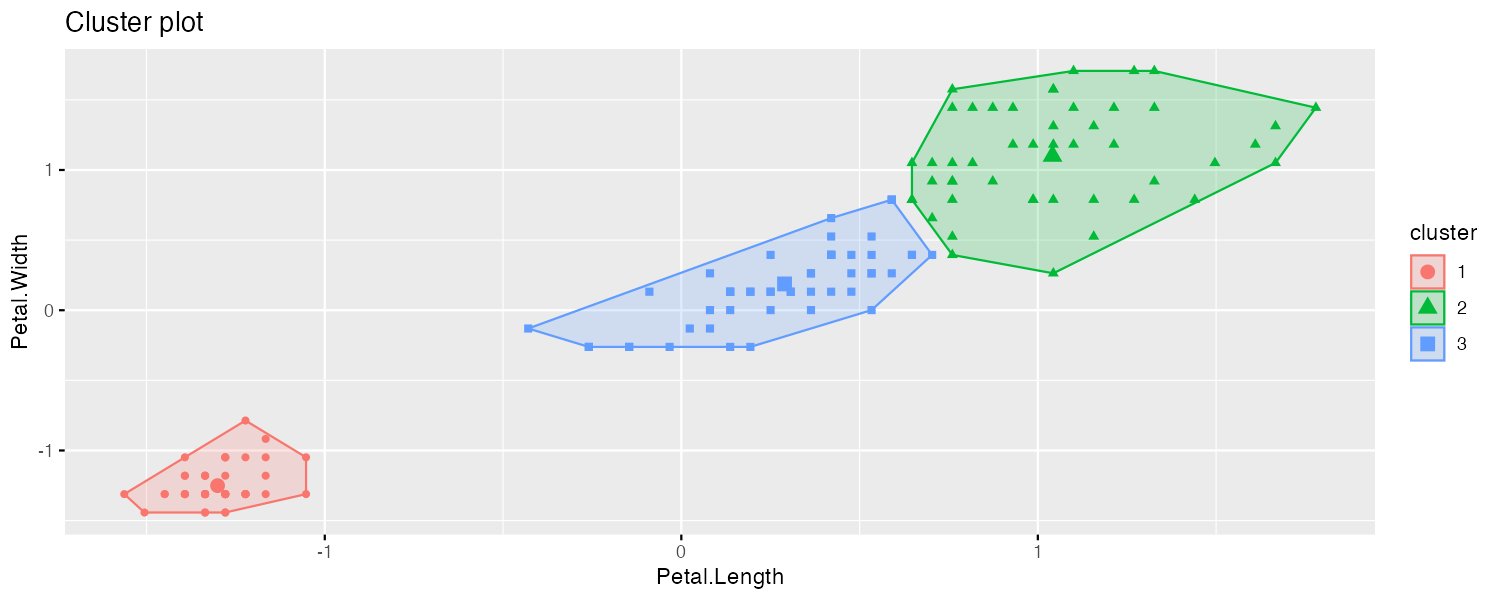
层次聚类
层次聚类(hierarchical clustering)不同于 K-means 那种基于划分的聚类,通过对数据集在不同层次上进行划分,直至达到某种条件。层次聚类根据分层的方法不同,可以分为凝聚(agglomerative)层次聚类和分裂(divisive)层次聚类。
AGNES(Agglomerative Nesting)算法是一种凝聚层次聚类算法,其基本思想如下:
- 将数据集中每个样本作为一个簇。
- 在每一轮计算中,找出两个距离最近的簇进行合并,生成一个新的簇。
- 重复步骤 2,直至达到预设的聚类簇的个数。
层次聚类
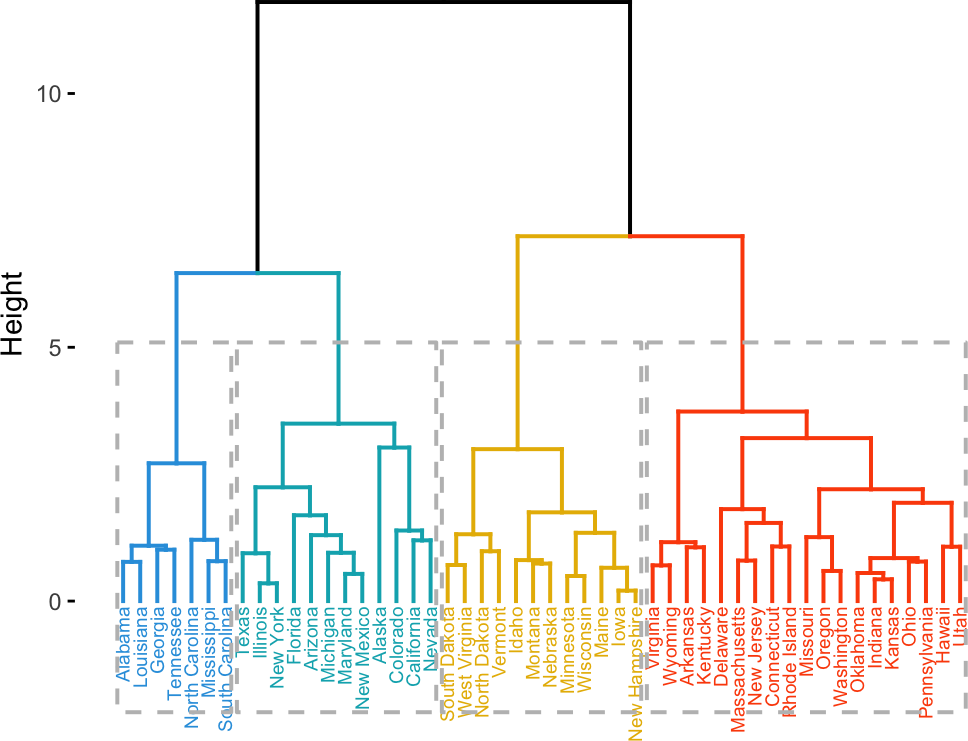
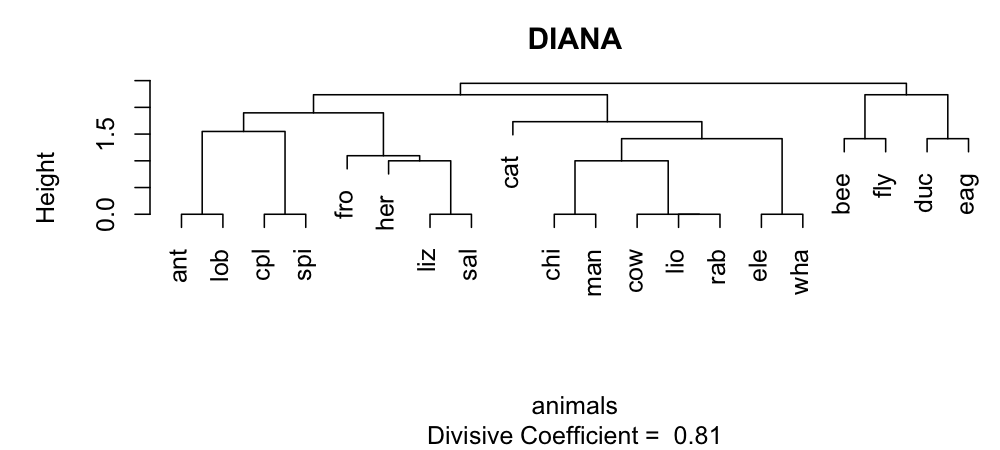
利用 AGNES 和 DIANA 算法对 animals 数据集进行层次聚类分析,可以得到层次聚类分析的树状图(dendrogram),如图所示:
library(cluster)
data("animals")
animals_agnes <- agnes(animals)
plot(animals_agnes, which.plot = 2,
main = "AGNES 算法")
animals_diana <- diana(animals)
plot(animals_diana, which.plot = 2,
main = "DIANA 算法")
基于密度的聚类
核心点(core point)
对于 \(x \in D\),若 \(\rho \left(x\right) \geq MinPts\),则称 \(x\) 为一个核心点。假设 \(D\) 中所有核心点构成的集合为 \(D_{core}\),记 \(D_{n-core} = D \setminus D_{core}\) 为所有非核心点的集合。
边界点(border point)
对于 \(x \in D_{n-core}\),且 \(\exists y \in D\),满足 \[y \in N_\epsilon \left(x\right) \cap D_{core}\] 即点 \(x\) 所在的 \(\epsilon\) 邻域中存在核心点,则称 \(x\) 为 \(D\) 的边界点,记所有的边界点的集合为 \(D_{border}\)。
噪音点(noise point)
记 \(D_{noise} = D \setminus \left(D_{core} \cup D_{border}\right)\),对于 \(x \in D_{noise}\),则称 \(x\) 为噪音点。
核心点,边界点和噪音点示例如图所示:

其中 \(C\) 为 6 个核心点,\(B_1\) 和 \(B_2\) 为 2 个边界点,\(N\) 为 1 个噪音点。
基于密度的聚类
相比 K-means 算法,DBSCAN 算法有如下优势:
- 不需要事先指定簇的个数 \(k\)。
- 可以发现任意形状的簇。
- 对噪音数据不敏感。
尽管相比 K-means,DBSCAN 算法有很多优势,但是对于不同的数据集,DBSCAN 算法的参数 \(\epsilon\) 和 \(MinPts\) 有时很难选取和优化。
一个非球形簇的数据分别利用 DBSCAN 算法和 K-means 算法进行聚类分析,对比结果如图所示:


基于密度的聚类
points_plt <- dplyr::bind_cols(
points,
Cluster=as.factor(points_dbscan$cluster)
)
ggplot(points_plt, aes(x, y)) +
geom_point(aes(color = Cluster, shape = Cluster))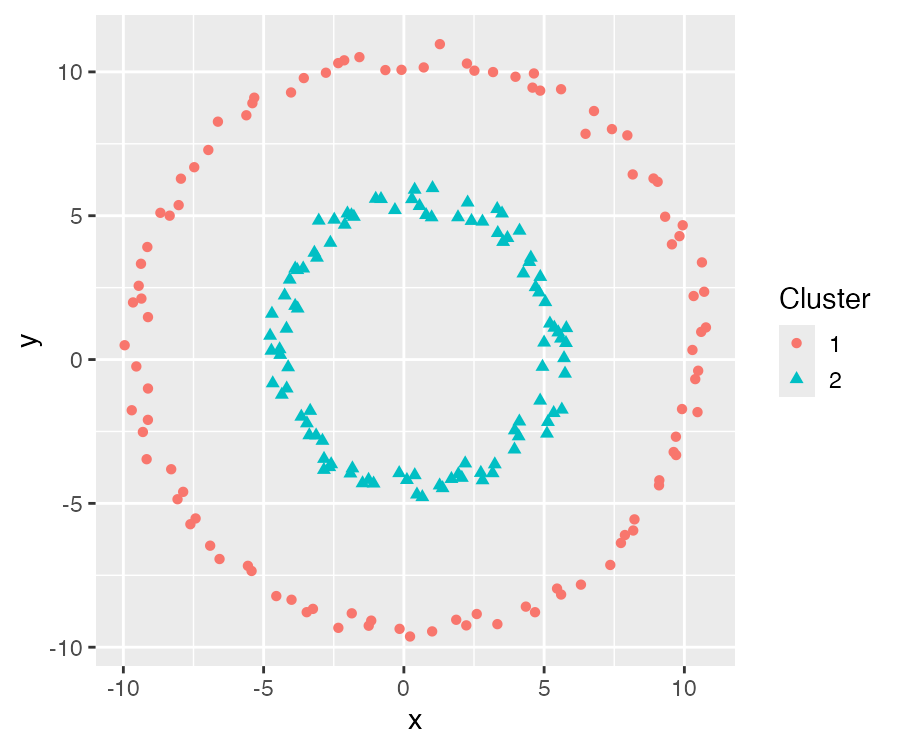
感谢倾听
本作品采用  授权
授权
版权所有 © 范叶亮 Leo Van