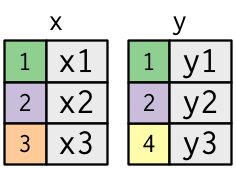
x <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
3, "x3"
)数据分析基础 (下)
Data Analytics Introduction - Part 2
关系数据处理
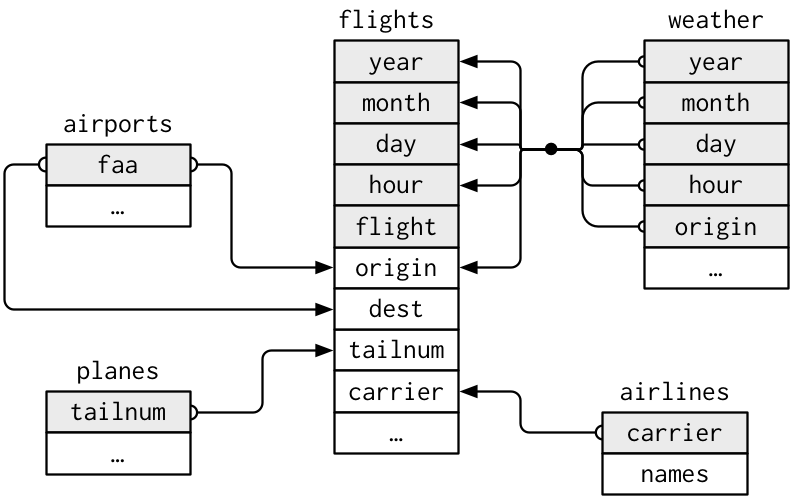
下面将使用 nycflights13 包来介绍关系数据处理。nycflights13 中包含了与 flights 相关的 4 组数据,关系如下图所示:
合并连接
合并连接可以将两个表格中的变量组合起来,它先通过两个表格的键匹配观测,然后将一个表格中的变量复制到另一个表格中。和 mutate() 函数一样,连接函数也会将变量添加在表格的右侧,因此如果表格中已经有了很多变量,那么新变量就不会显示出来。
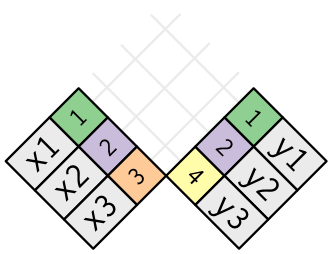
为了帮助掌握连接的工作原理,在此介绍用图形来表示连接的一种方法。
有颜色的列表示作为“键”的变量:它们用于在表间匹配行。灰色列表示“值”列,是与键对应的值。
y <- tribble(
~key, ~val_y,
1, "y1",
2, "y2",
4, "y3"
)
合并连接
在以下的示例中,虽然键和值都是一个变量,但非常容易推广到多个键变量和多个值变量的情况。
连接是将 x 中每行连接到 y 中 0 行、一行或多行的一种方法。
右图表示出了所有可能的匹配,匹配就是两行之间的交集。
内连接
内连接是最简单的一种连接。只要两个观测的键是相等的,内连接就可以匹配它们。
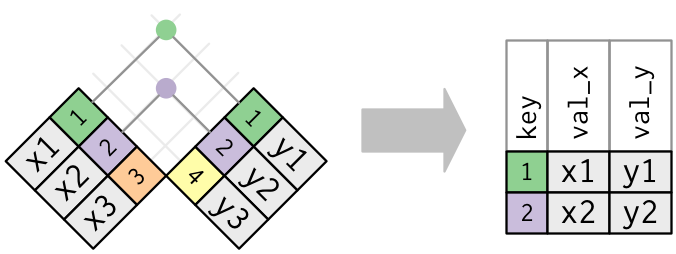
内连接最重要的性质是,没有匹配的行不会包含在结果中。这意味着内连接一般不适合在分析中使用,因为太容易丢失观测了。
内连接的结果是一个新数据框,其中包含键、x 值和 y 值。使用 by 参数告诉 dplyr 哪个变量是键:
x |>
inner_join(y, by = "key")# A tibble: 2 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2 外连接
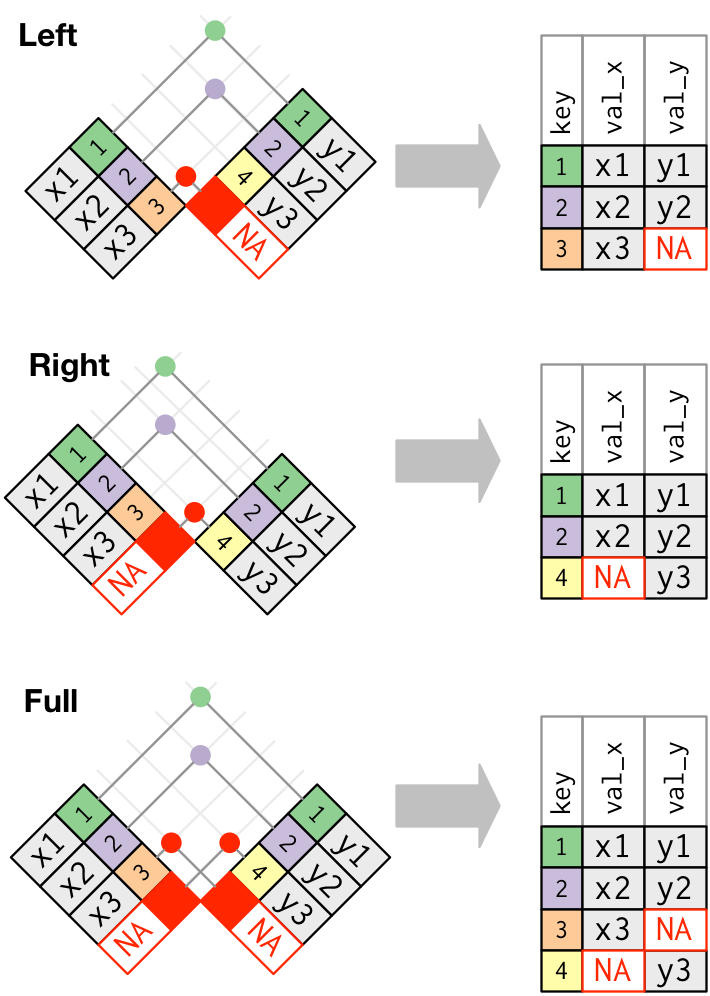
内连接保留同时存在于两个表中的观测,外连接则保留至少存在于一个表中的观测。外连接有 3 种类型。
- 左连接:保留
x中的所有观测 - 右连接:保留
y中的所有观测 - 全连接:保留
x和y中的所有观测
这些连接会向每个表中添加额外的“虚拟”观测,这个观测拥有总是匹配的键(如果没有其他键可匹配的话),其值则用 NA 来填充。
最常用的连接是左连接:只要想从另一张表中添加数据,就可以使用左连接,因为它会保留原表中的所有观测,即使它没有匹配。
重复键
至今为止,所有图都假设键具有唯一性,但情况并非总是如此。
一张表中具有重复键。通常来说,当存在一对多关系时,如果向表中添加额外信息,就会出现这种情况。
x <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
2, "x3",
1, "x4"
)y <- tribble(
~key, ~val_y,
1, "y1",
2, "y2"
)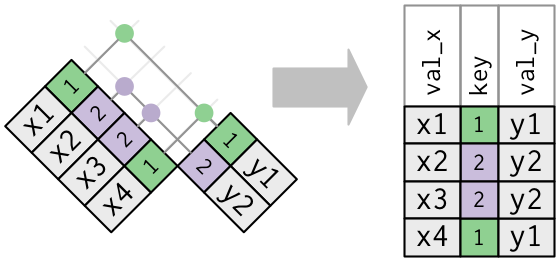
left_join(x, y, by = "key")# A tibble: 4 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 2 x3 y2
4 1 x4 y1 重复键
两张表中都有重复键。这通常意味着出现了错误,因为键在任意一张表中都不能唯一标识观测。
当连接这样的重复键时,你会得到所有可能的组合,即笛卡儿积:
x <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
2, "x3",
3, "x4"
)y <- tribble(
~key, ~val_y,
1, "y1",
2, "y2",
2, "y3",
3, "y4"
)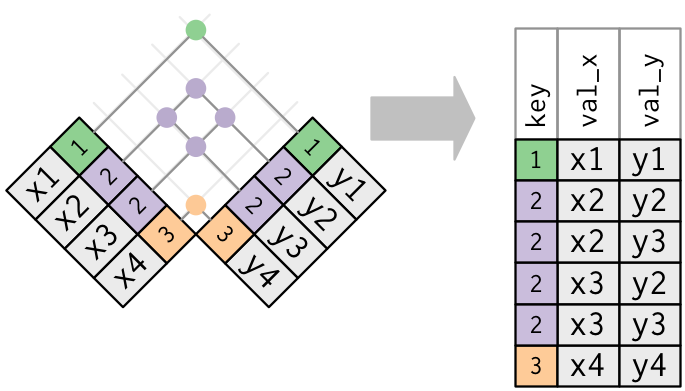
left_join(x, y, by = "key")# A tibble: 6 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 2 x2 y3
4 2 x3 y2
5 2 x3 y3
6 3 x4 y4 筛选链接
筛选连接匹配观测的方式与合并连接相同,但前者影响的是观测,而不是变量。筛选连接有两种类型。
semi_join(x, y):保留x表中与y表中的观测相匹配的所有观测。anti_join(x, y):丢弃x表中与y表中的观测相匹配的所有观测。
半连接的图形表示如下所示。
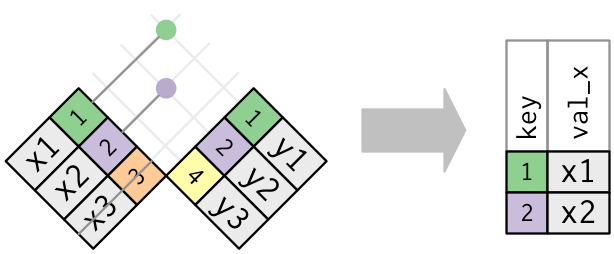
重要的是存在匹配,匹配了哪条观测则无关紧要。这说明筛选连接不会像合并连接那样造成重复的行。
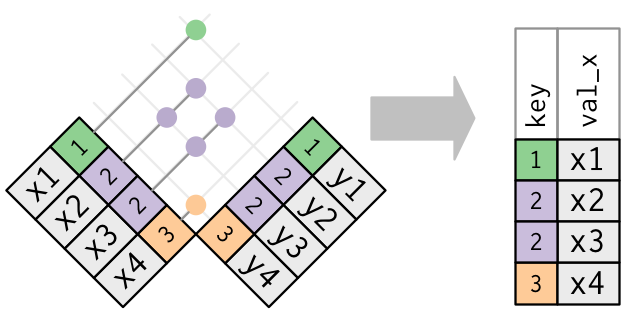
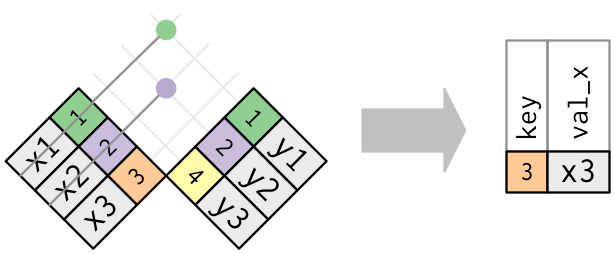
半连接的逆操作是反连接。反连接保留 x 表中那些没有匹配 y 表的行。
因子数据处理
在可视化中修改因子水平的顺序很有用。例如:假设需要探索不同民族的人每天平均看电视的时间:
relig_summary <- gss_cat |>
group_by(relig) |>
summarise(
age = mean(age, na.rm = TRUE),
tvhours = mean(tvhours, na.rm = TRUE),
n = n()
)ggplot(relig_summary, aes(tvhours, relig)) +
geom_point()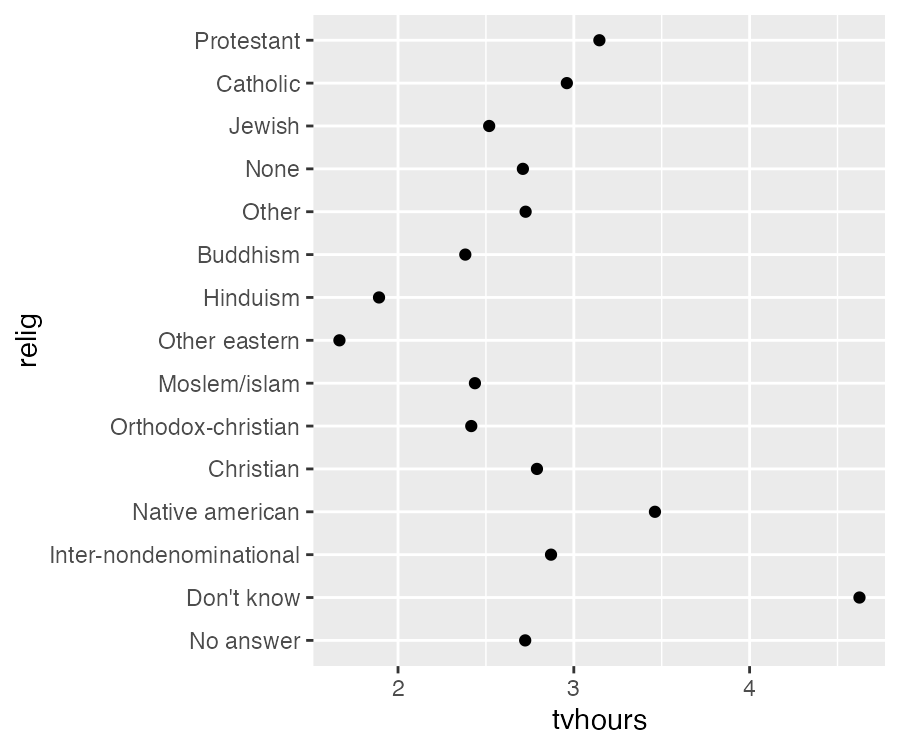
因子数据处理
由于没有整体的模式,因此很难解释上图。通过 fct_reorder() 可以重新对民族的因子水平进行重排。fct_reorder() 接受 3 个参数:
f:需要重排的因子x:用于重排的数值向量fun:可选参数,当对于f有多个x值时,所采用的计算方式,默认为median
ggplot(relig_summary,
aes(tvhours, fct_reorder(relig, tvhours))) +
geom_point()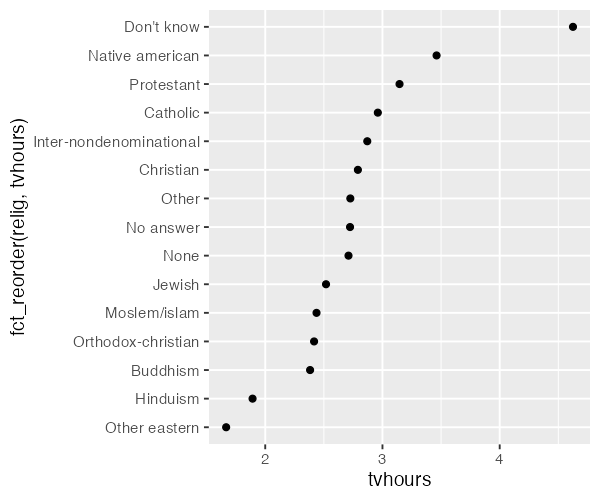
多参数映射
但是这种方法很难让人理解代码的本意。相反,我们应该使用 map2() 函数,它可以对两个向量进行同步迭代:
map2(mu, sigma, rnorm, n = 5) |> str()List of 3
$ : num [1:5] 4.81 3.45 7.61 5.2 4.53
$ : num [1:5] 2.33 16.7 9.76 3.39 3.94
$ : num [1:5] -6.68 5.32 -5.29 -9.33 9.93map2() 函数可以生成以下一系列函数调用:
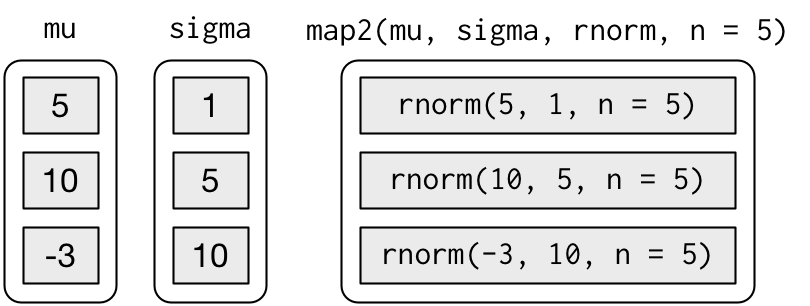
注意,每次调用时值发生变化的参数(这里是 mu 和 sigma)要放在映射函数(这里是 rnorm)的前面,值保持不变的参数(这里是 n )要放在映射函数的后面。
多参数映射
purrr 提供了 pmap() 函数,它可以将一个列表作为参数。如果你想生成均值、标准差和样本数量都不相同的正态分布,那么就可以使用这个函数:
n <- list(1, 3, 5)
args1 <- list(n, mu, sigma)
args1 |>
pmap(rnorm) |>
str()List of 3
$ : num 5.86
$ : num [1:3] 13.56 7.57 15.93
$ : num [1:5] 14.99 5.52 -6.41 -28.28 3.49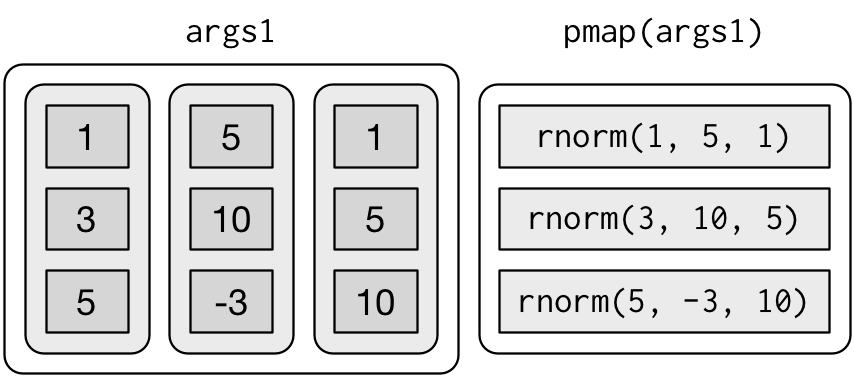
多参数映射
如果没有为列表的元素命名,那么 pmap() 在调用函数时就会按照位置匹配。这样做比较容易出错,而且会让代码的可读性变差,因此最好使用命名参数:
args2 <- list(mean = mu, sd = sigma, n = n)
args2 |>
pmap(rnorm) |>
str()List of 3
$ : num 5.65
$ : num [1:3] 8.58 14.07 -0.81
$ : num [1:5] -2.48 19.77 -1.13 -9.35 3.85这样生成的函数调用更长一些,但更安全:
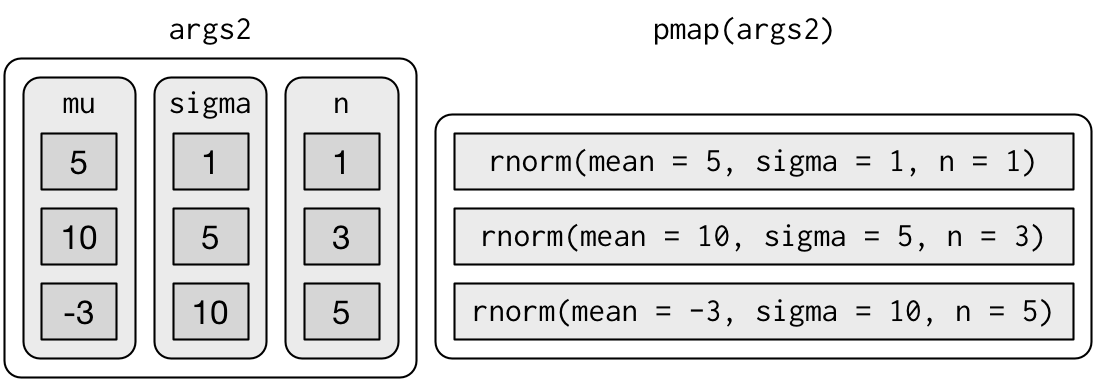
多参数映射
还有一种更复杂的情况:不但传给函数的参数不同,甚至函数本身也是不同的。为了处理这种情况,你可以使用 invoke_map() 函数:
f <- c("runif", "rnorm", "rpois")
param <- list(
list(min = -1, max = 1),
list(sd = 5),
list(lambda = 10)
)
invoke_map(f, param, n = 5) |> str()List of 3
$ : num [1:5] 0.7273 -0.2082 0.0732 0.6064 0.8865
$ : num [1:5] -0.299 0.994 5.469 2.637 -6.994
$ : int [1:5] 5 15 6 13 16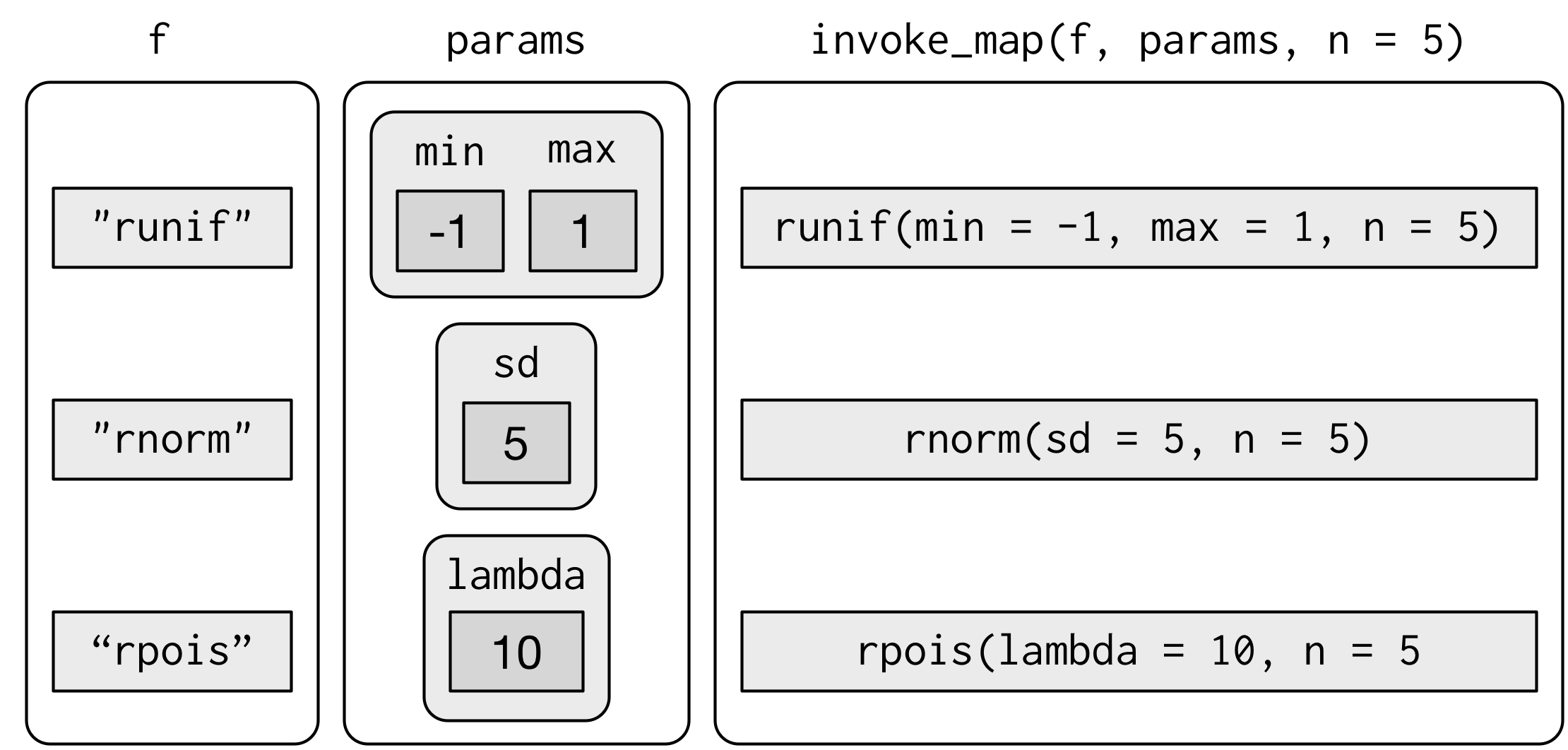
第一个参数是一个函数列表或包含函数名称的字符向量。第二个参数是列表的一个列表,其中给出了要传给各个函数的不同参数。随后的参数要传给每个函数。
感谢倾听
本作品采用  授权
授权
版权所有 © 范叶亮 Leo Van